Automate Review Apps
Gander automatically deploys a review app based on your GitHub code every time you make a pull request. A comment appears on your pull request with a live, shareable link to your review app.
MENU


Automatically deploy
isolated
review apps for
every pull request
Gander automatically deploys a review app based on your GitHub code every time you make a pull request. A comment appears on your pull request with a live, shareable link to your review app.
Gander containerizes review apps into isolated environments and automatically disposes of them after the pull request is closed.
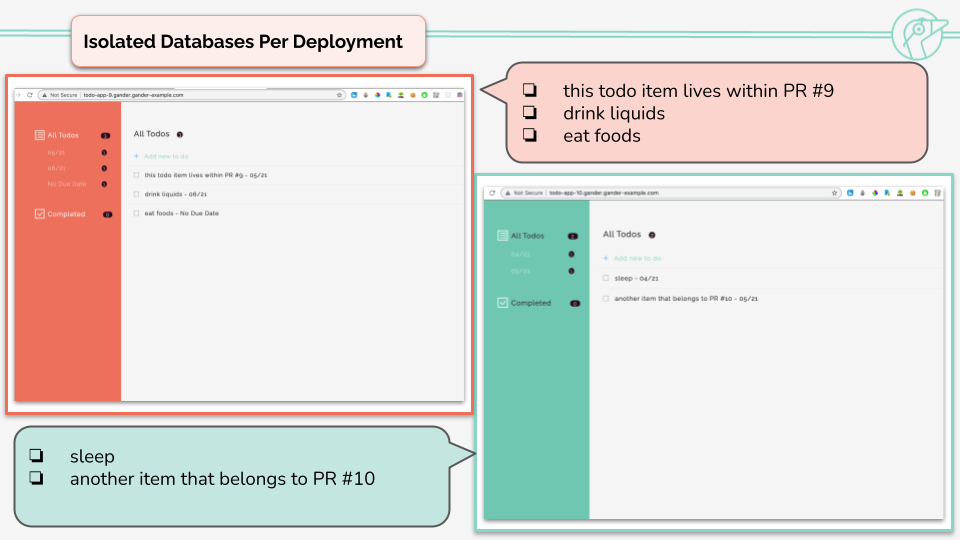
Gander provides each review app with its own database server, so that you can test the functionality of each pull request with its own independently persisted data.
Gander allows developers to create temporary deployments of their latest code changes upon creating a pull request. These deployments, known as "review apps", serve as isolated environments to visually examine UI changes and interactively test new and updated behaviours. Because these deployments are accessible via a shareable link, reviewers no longer have to download the code base and build the application, and developers can easily include non-technical stakeholders in these reviews.
Built on top of GitHub Actions, AWS, and Node.js, Gander creates infrastructure for hosting your review apps and fully automates the process of spinning up, managing, and tearing them down. Gander is open-source, self-hosted, and ready to use within minutes of installation.
Gander is a tool to automate review apps and ultimately make the code review process more convenient for developers and more accessible to non-technical team members. We designed Gander with the following goals in mind:
As review apps are tools to make the development and reviewing processes more convenient, we strove to make Gander as easy to use and as configuration-free as possible. Simply bring a code repository and your AWS credentials, and Gander takes care of the rest. With a simple command in our CLI and no required config files, Gander users can:
In addition to automating all builds and tear downs, Gander:
Currently, Gander only supports:
Review apps are ephemeral apps, meaning they're temporary deployments with a self-contained version of your app. 1, 2 Generally speaking, these apps are created on demand each time a feature needs to be reviewed and then automatically deleted when the review is completed and the pull request is closed. 1
Review apps are easily shared, making it possible to include not only developers, but also non-technical reviewers during development. Team members such as designers, project managers, and clients can receive a link, try out new features in a browser and give feedback. 3
Review Apps provide easier and better testing for features and fixes in isolation . . . [They] speed up team decision-making so that you can deliver better apps faster, and with greater confidence.
- Heroku Pipelines 3, 4
When developing a new feature, developers typically follow some development cycle like the following:
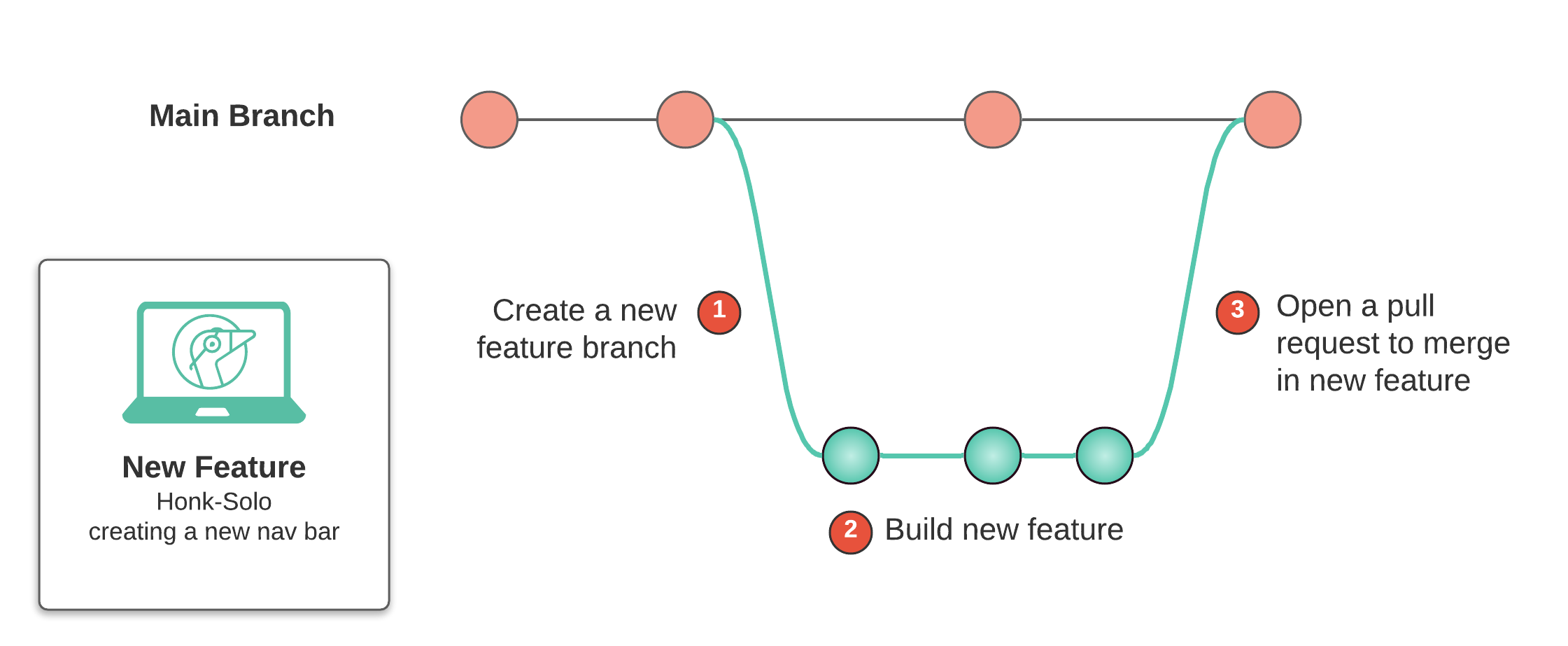
After the feature is merged back into the main branch, this feature will typically go through some development pipeline, which may include stages such as testing, QA checks, and deploying the application to a staging environment meant to mimic production conditions. The new feature is only reviewed visually in the later stages of the pipeline, possibly as late as the deployment to the staging environment.
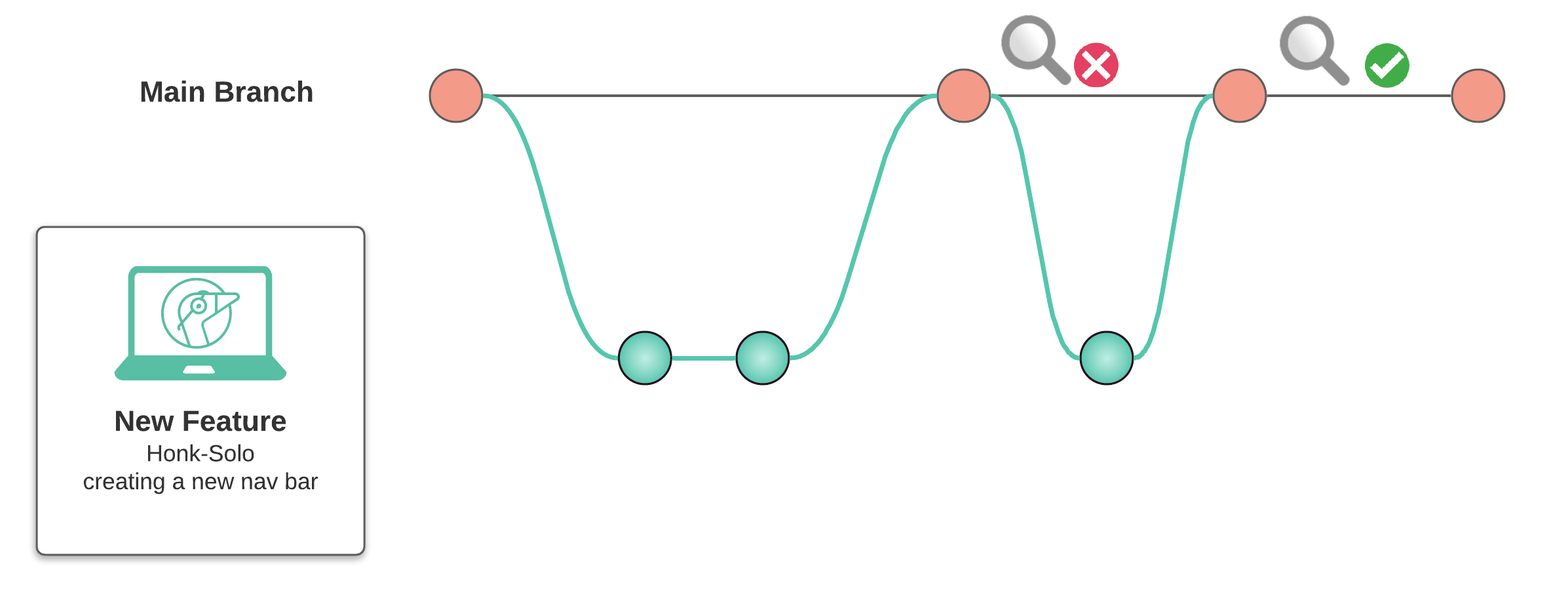
Thus, without review apps, non-technical stakeholders are only involved within the reviewing process after the code is merged, the PR is closed, and the app is deployed to some viewing environment such as staging. This means if there's an issue with some new feature, our developer would have to repeat the development cycle of branching, developing and merging before receiving another review. Moreover, the code itself would have to go through all the stages of the development pipeline before being viewed once again. 1
Review apps provide an easy way to shorten the feedback loop between developers and non-developers. With review apps, our developer's cycle from above may now look something like this:
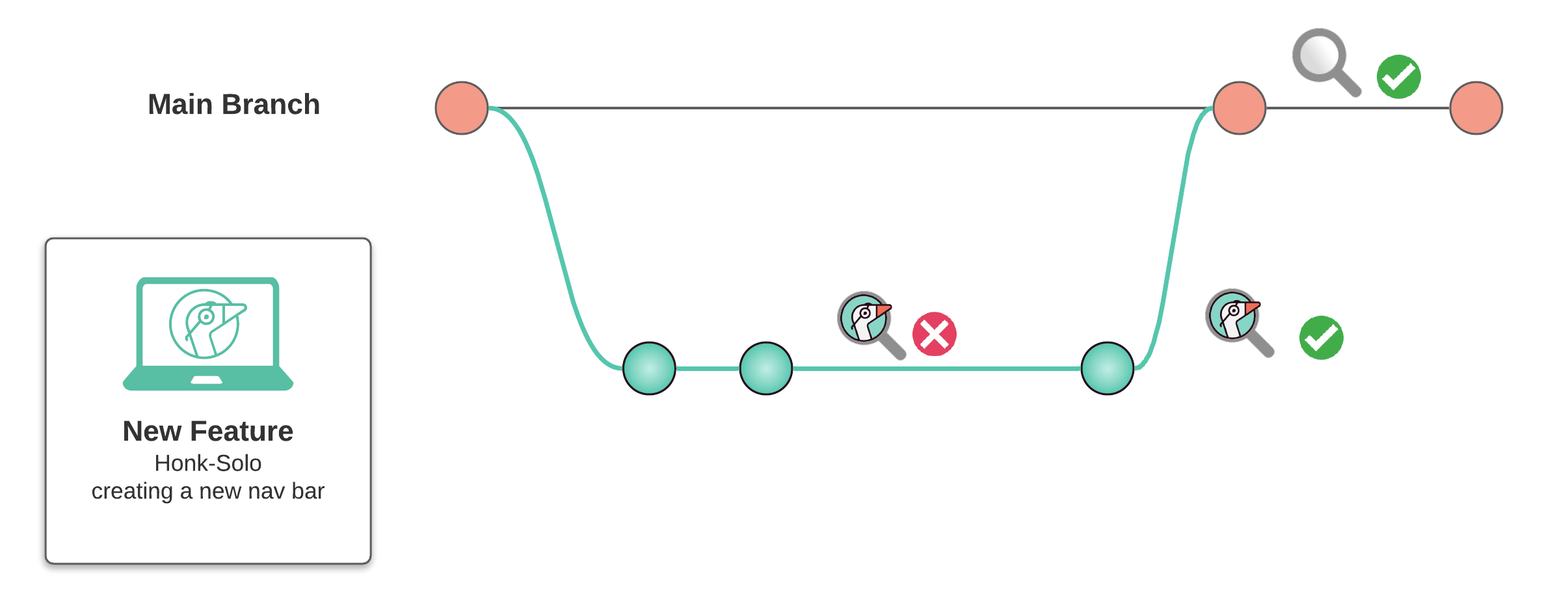
Before merging the feature into the main branch, we can create a review app and share it with other developers, designers, and clients for a truly well-rounded review process involving all stakeholders. Developers viewing the code will no longer have to guess what the code does, as they can interact with the application directly in their browser. 3 Designers can see how their creations integrate with users' interactions and experiences. Clients can step into their users' shoes and truly understand the digital experience created from their guidelines.
Most importantly, by involving more team members earlier within the development process, review apps can shorten the feedback loop and speed up the time for development. 4 This means that buggy code can be caught earlier in the process by QA teams, and never gets merged in the first place. This leads to a higher velocity of development, leading to an overall reduced cost of development.
All in all, review apps are a convenient tool to help developers:
Generally speaking, there are two categories of review app solutions:
The first category is review apps as a feature of a larger service. For example, products like Heroku Pipelines provide review apps as one part of a full continuous delivery pipeline they call Heroku Flow. For some users, this would be an excellent fit, due to the convenience of delegating all stages of the development pipeline to a service. However, this solution will not be the right fit for all developers, as using such pipeline services imposes certain restrictions upon the user:
GitLab Review Apps offer a solution similar to Heroku's, with the distinction that GitLab is open-source. Otherwise, the tradeoffs are similar, as the user must use GitLab as a code-hosting service in order to take advantage of their review app feature.
For developers looking for just a simple review app solution and not a whole development pipeline or code-hosting service, review applications as a feature aren't an ideal solution.
The second category is review apps as a service. Services like Tugboat 5 and Reploy 6 offer a proprietary, configurable platform for deploying and managing review apps. These platforms include many useful features beyond simply deploying a review app, such as customized build steps and integrations with other services. However, using a feature-rich review app platform does come with certain limitations:
For developers looking for an easily configurable solution where they can maintain control and pay as they go, review apps as a service is not really a good fit.
The following table summarizes the attributes of these two types of review app solutions:
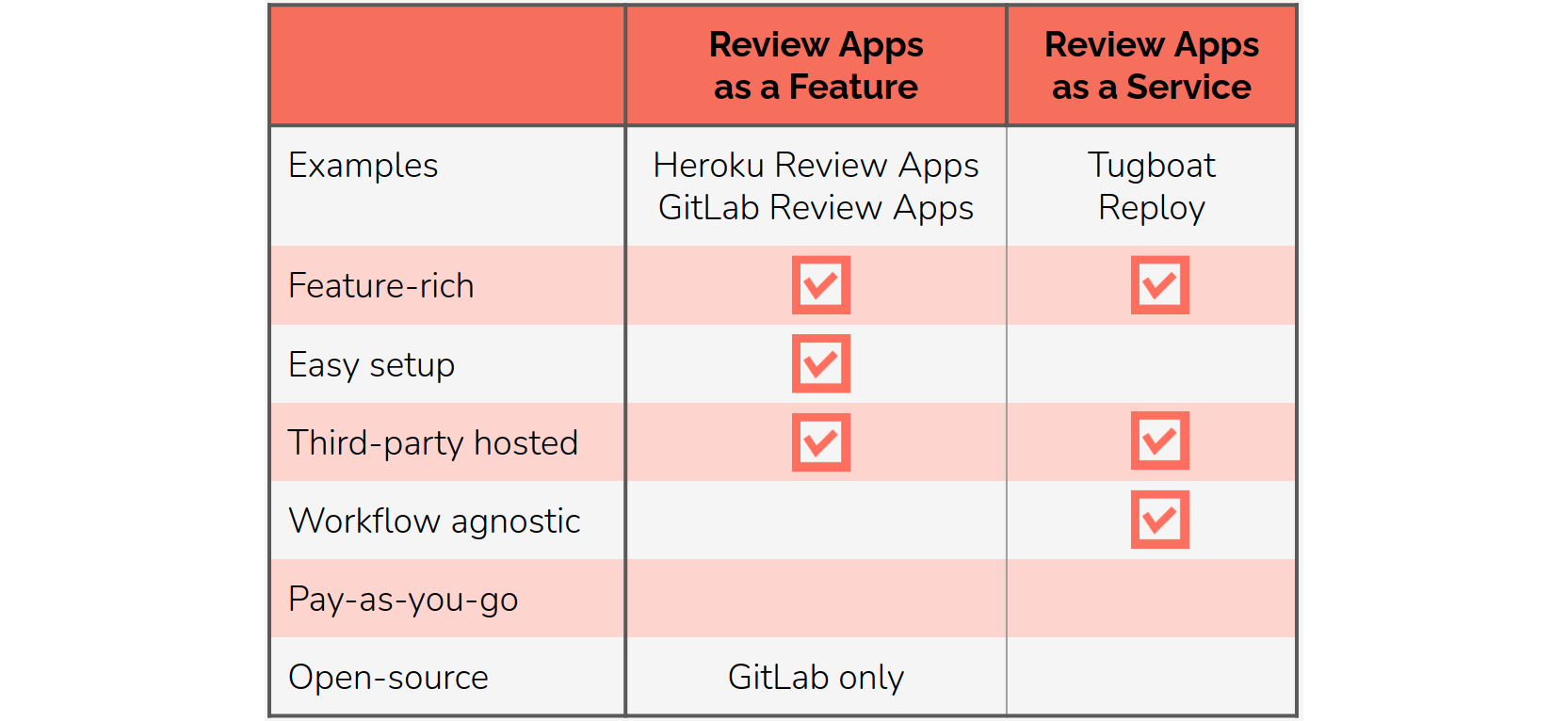
In spite of the generous feature sets offered by these solutions, they won't be the best fit for all development teams. If a team wants to deploy review apps without much change to their CI/CD pipeline, they won't be able to do that with a solution like Heroku's, because they impose their own pipeline model. If they want to be able to control the infrastructure their review apps are hosted on, due to security or compliance, they won't find a solution there either. Additionally, if they want a pay-as-you-go model instead of a monthly fee, these solutions are not the correct fit.
For developers looking for a solution that keeps their code within their own network and whose only costs are those with their cloud provider, one option is to build your own in-house automated review app solution. However, building such a solution requires quite a few steps.
Starting with a smaller problem, we can examine the number of steps required to deploy just one application. This results in a list of at least 13 individual steps.
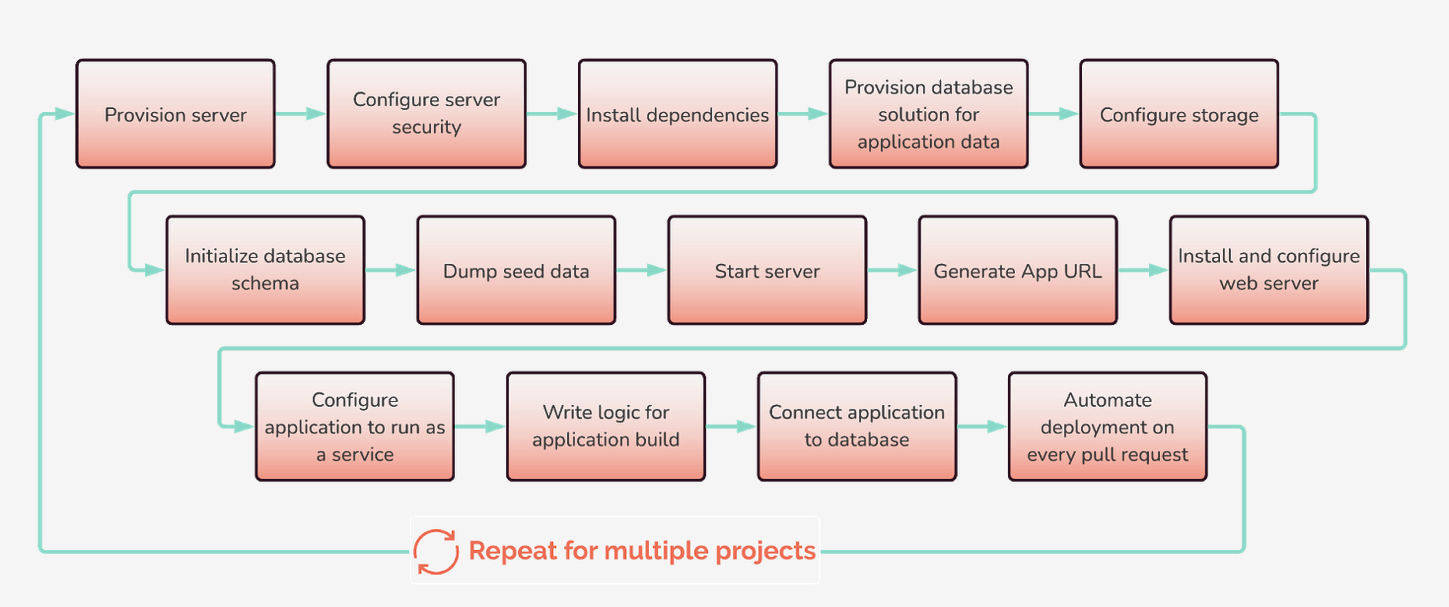
To reach a complete review app solution, we still have quite a few considerations to make:
With these considerations above, we ideally want to have some easy way to provision long-lived infrastructure when we want to create review apps frequently, and an easy way to tear down the infrastructure when we reach a development lull. We'd also want to find a way to isolate review apps and their databases from one another, whether it be deploying each app on a different server or containerizing applications. In addition, we would need to provision and configure some kind of storage method for each review app and create some method to automate all these processes.
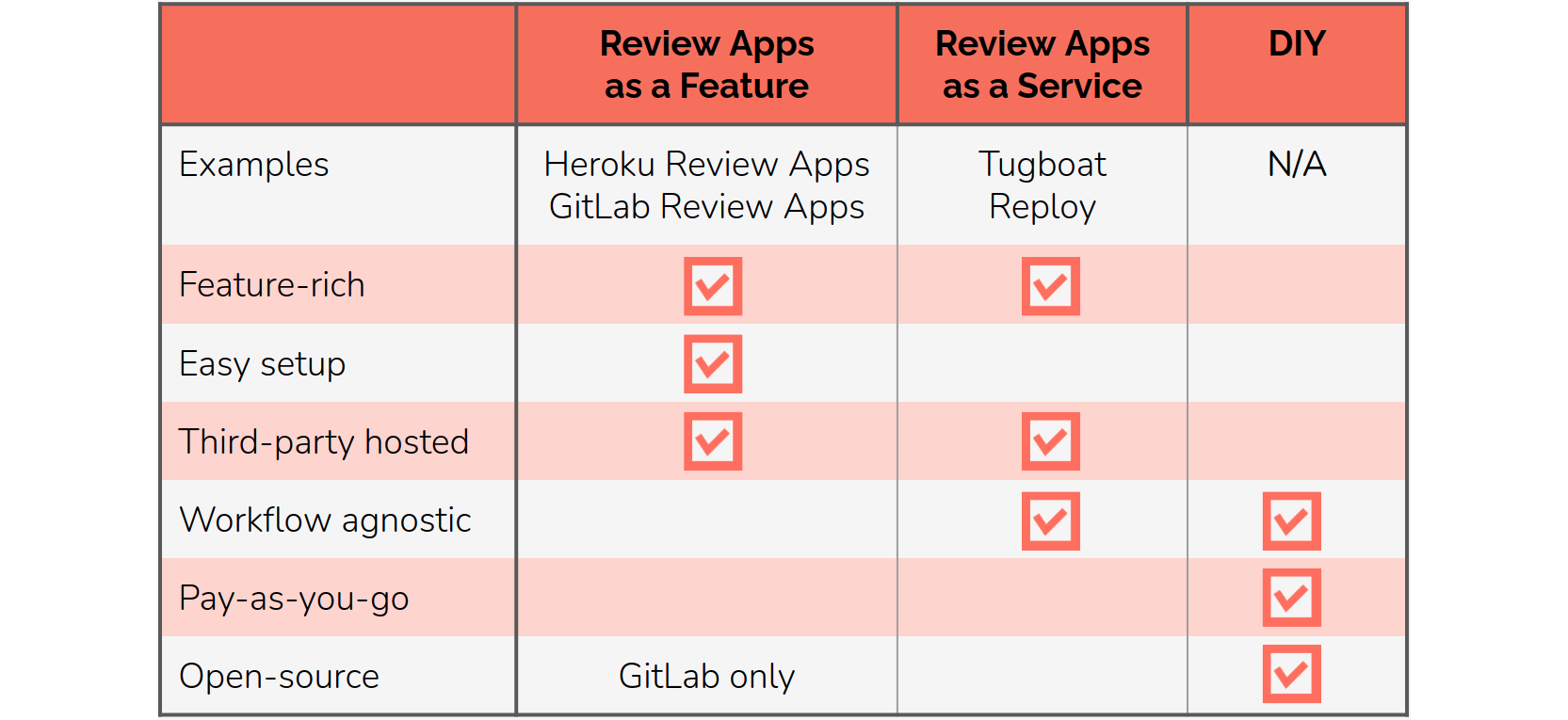
This DIY approach fulfills the goals of keeping code within your own network and keeping costs transparent. However, creating such a DIY solution is a large undertaking. For organizations that still want this type of solution, it would be ideal to have a customizable open-source option that provided these same benefits without the time and development costs of creating it from scratch. This is why we built Gander.
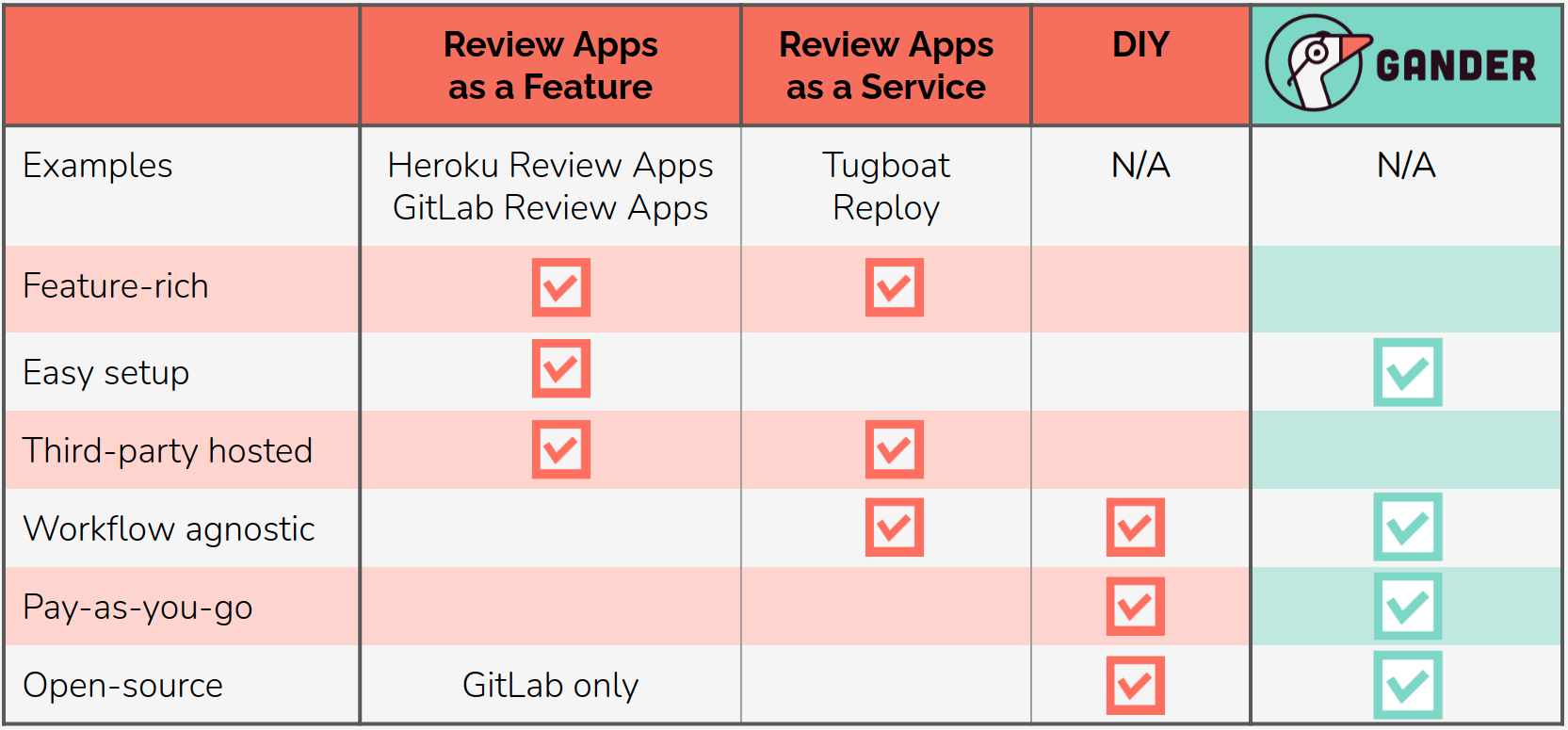
Gander fills its niche by achieving the design goals we established earlier.
In the remaining sections, we discuss the decisions we made in order to architect a system that meets these goals.
Gander uses AWS infrastructure combined with GitHub Actions to build and host review apps. We're going to do a quick overview of this architecture, and then revisit each piece to explore the design decisions that went into it.
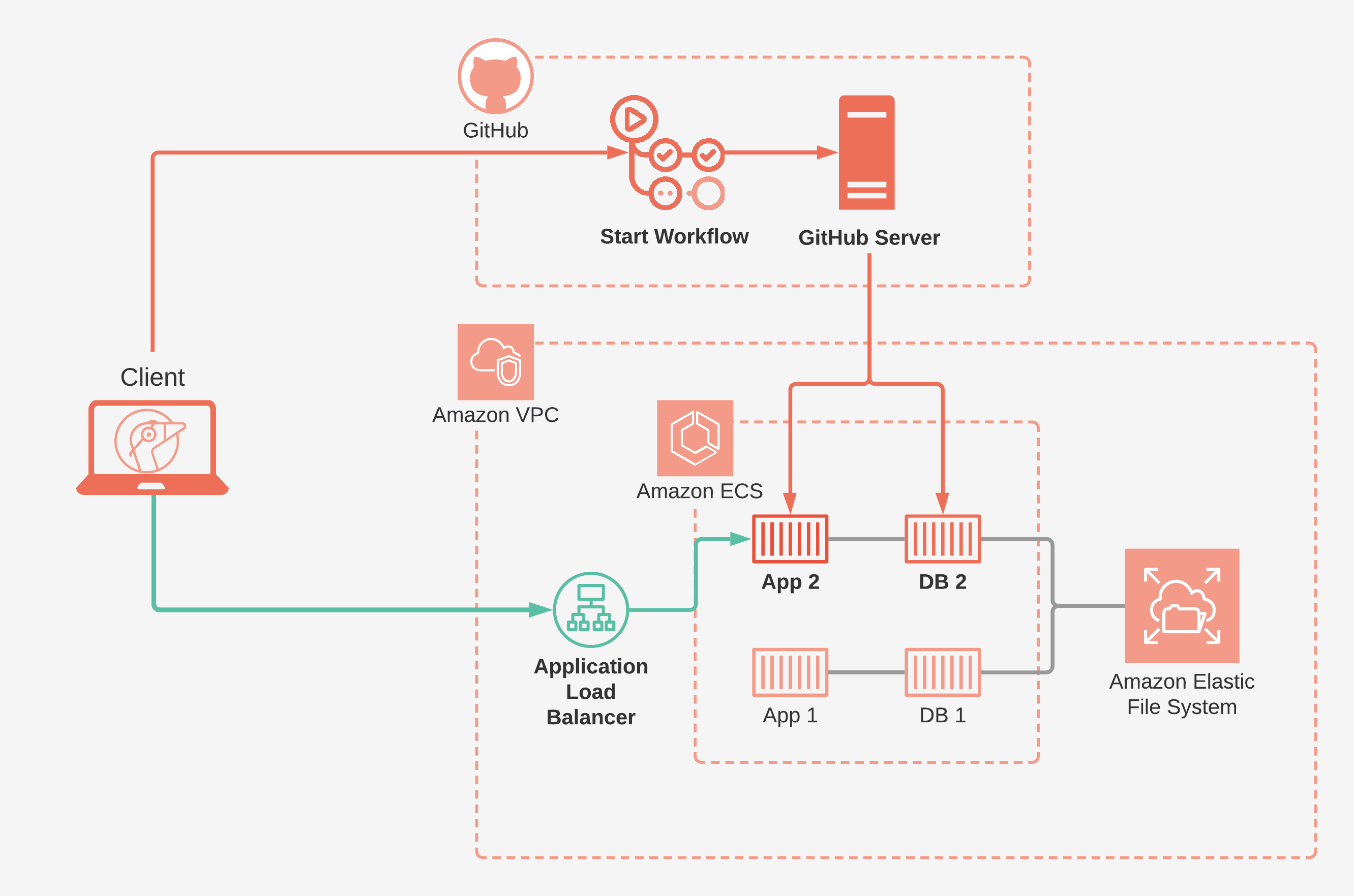
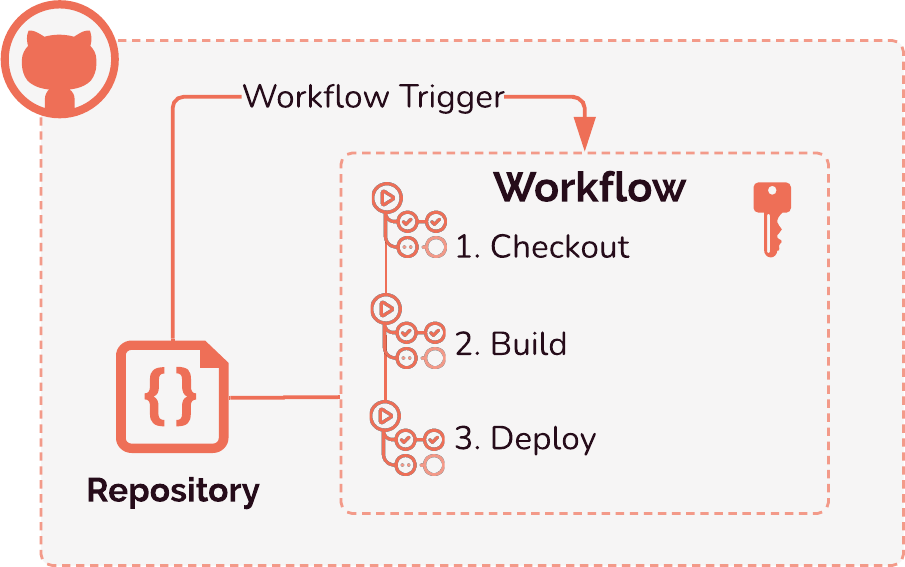
To build and remove your review apps, we leverage GitHub Actions, a workflow automation tool available from GitHub. In Gander's case, our workflows:
AWS provides all of the infrastructure required to effortlessly host, manage and view your review apps.
Gander provides a CLI so users can set up and tear down Gander infrastructure, and initialize repositories with Gander.
We'll begin our exploration of Gander's architecture with a look at how we leverage GitHub and GitHub Actions to respond to pull requests.
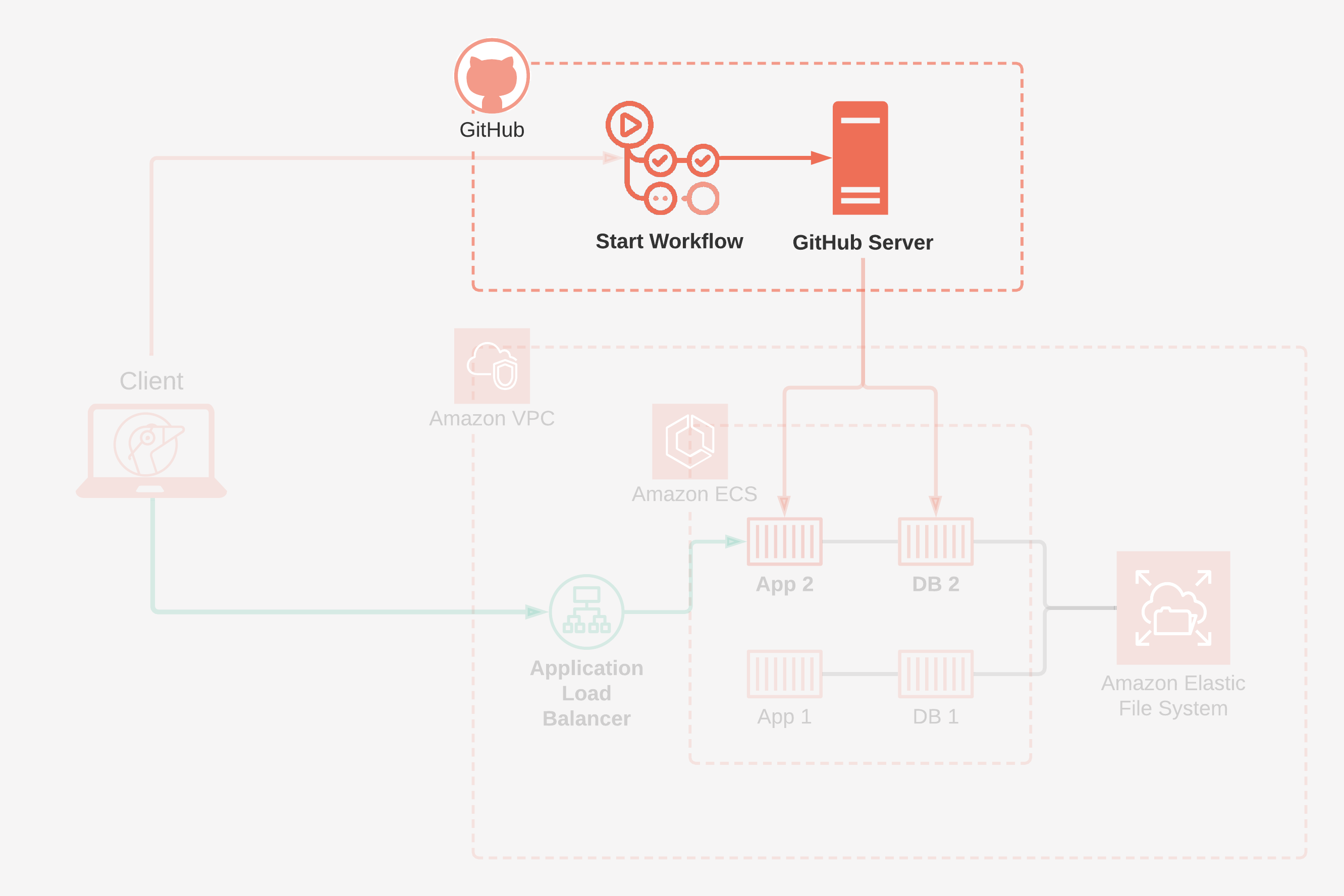
Before building and deploying review apps, we first have to decide the boundaries for this process:
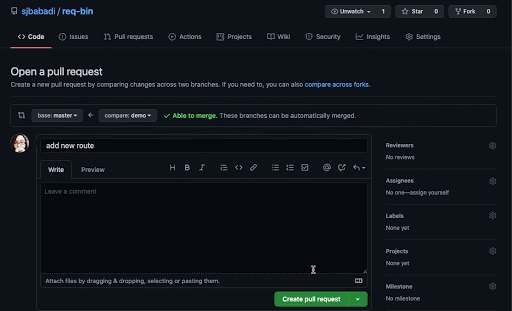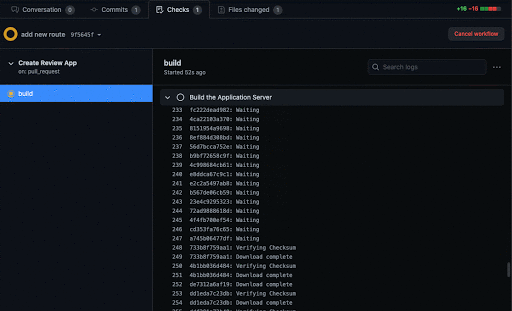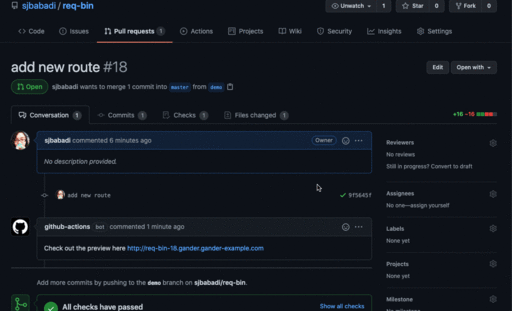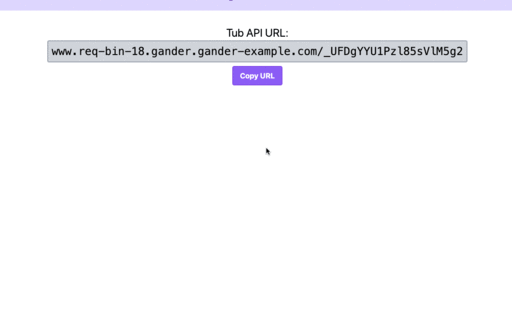
Given our goal of enabling relevant stakeholders to review new features earlier in development, pull requests are a perfect trigger for deploying review apps. Pull requests are a mechanism by which developers notify other team members that they have a completed feature ready for review. The feature is then reviewed and approved before being merged into a more stable branch of the codebase. 7
A typical lifecycle of a pull request looks something like this:
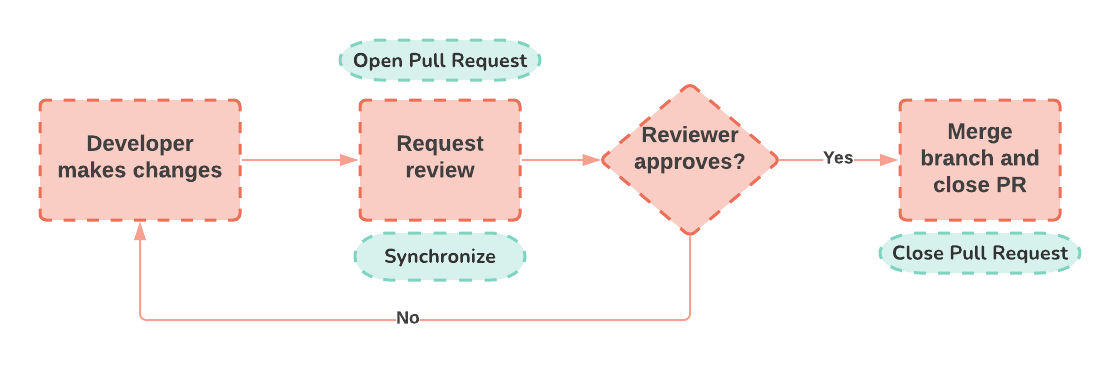
Since the purpose of Gander review apps is to enable team members to preview changes in a live deployment before merging, we want to run builds not only upon the opening of a pull request, but also when a new commit is made to the source branch of an existing pull request. This event is called synchronizing. As for tearing down a review app, the natural event to respond to is the closing of a pull request.
After establishing the three events Gander review apps react to, we now need to consider:
Webhooks are a way for applications to send automatic notifications to other applications whenever a certain event occurs. These notifications usually take the form of a POST request containing a payload with any relevant metadata about the event. 8 GitHub enables webhook integrations that can send these POST requests to whatever endpoint the user specifies.
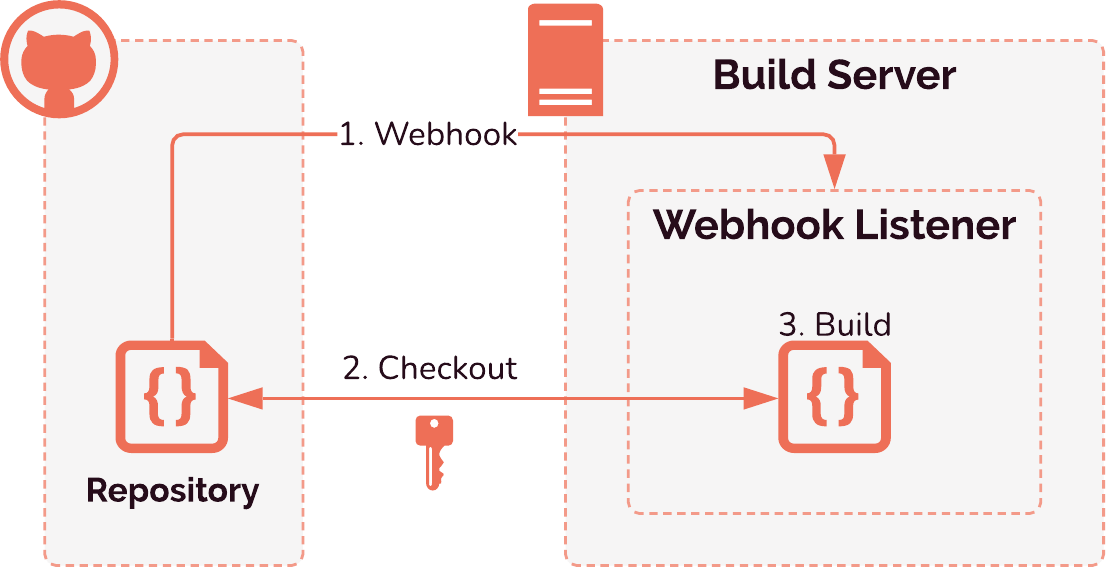
One way that we could have achieved our goal of a pull request trigger is by setting up a server whose purpose is to listen for a webhook event notifying that a pull request was opened, synchronized, or closed and to take action accordingly. To build a review app, this server would need to clone the relevant code from GitHub before it could do anything else. Doing it this way would allow more fine-grained control over the build environment — how the server itself is configured — but there are drawbacks to this approach.
First, this server would need to be online all of the time in order to listen for incoming webhook events. Outside of the time the server is actually building or tearing down a review app, it would be sitting idle. Considering that more time than not would be spent in this idle listening state, this is not resource-efficient or cost-effective.
Second, since this server would live outside the boundaries of GitHub, there would be an additional authentication step required before it is allowed to interact with the repository in any meaningful way. Then, any other metadata the server needs about the repository in order to carry out its work would require additional requests over the network to GitHub's API.
Thankfully, there is an alternative to webhooks that better suits our use-case — GitHub Actions. GitHub Actions is a workflow automation tool that executes on Github's servers, eliminating the need for our users to provision, maintain, and configure an entirely separate build server. Running our workflows on GitHub's servers through Actions also means that our users are not incurring any costs or consuming any compute resources when there is no build or tear-down to be run. GitHub Actions has a free tier available that contains 2000 minutes of compute per account per month, which can support between 200-300 pull requests per month depending on the size of your project.
Additionally, GitHub Actions allows us to run these workflows within the existing context of the users' repositories, eliminating the need to authenticate with the GitHub API. We can easily access information such as the pull request number and secrets within the repository. With a separate build server, accessing this information is still possible but would require additional network requests to the GitHub API. With GitHub Actions, we can access this information natively through the API built into the servers GitHub provides. Ultimately, because of the reduced costs and the convenience of executing code in the context of the repository, this is the clear choice for Gander, particularly since one of our major design goals was keeping expenses transparent and grounded in resource-use.
There are three workflows that we inject into a project — "Create review app", "Destroy review app", and "Update review app". Here is a brief summary of what each of those actions do:
Create Review App
Destroy Review App
Our Update workflow simply destroys a review app, then creates a new one with the updated code.
In the following sections, we'll cover what each of these steps involves in detail.
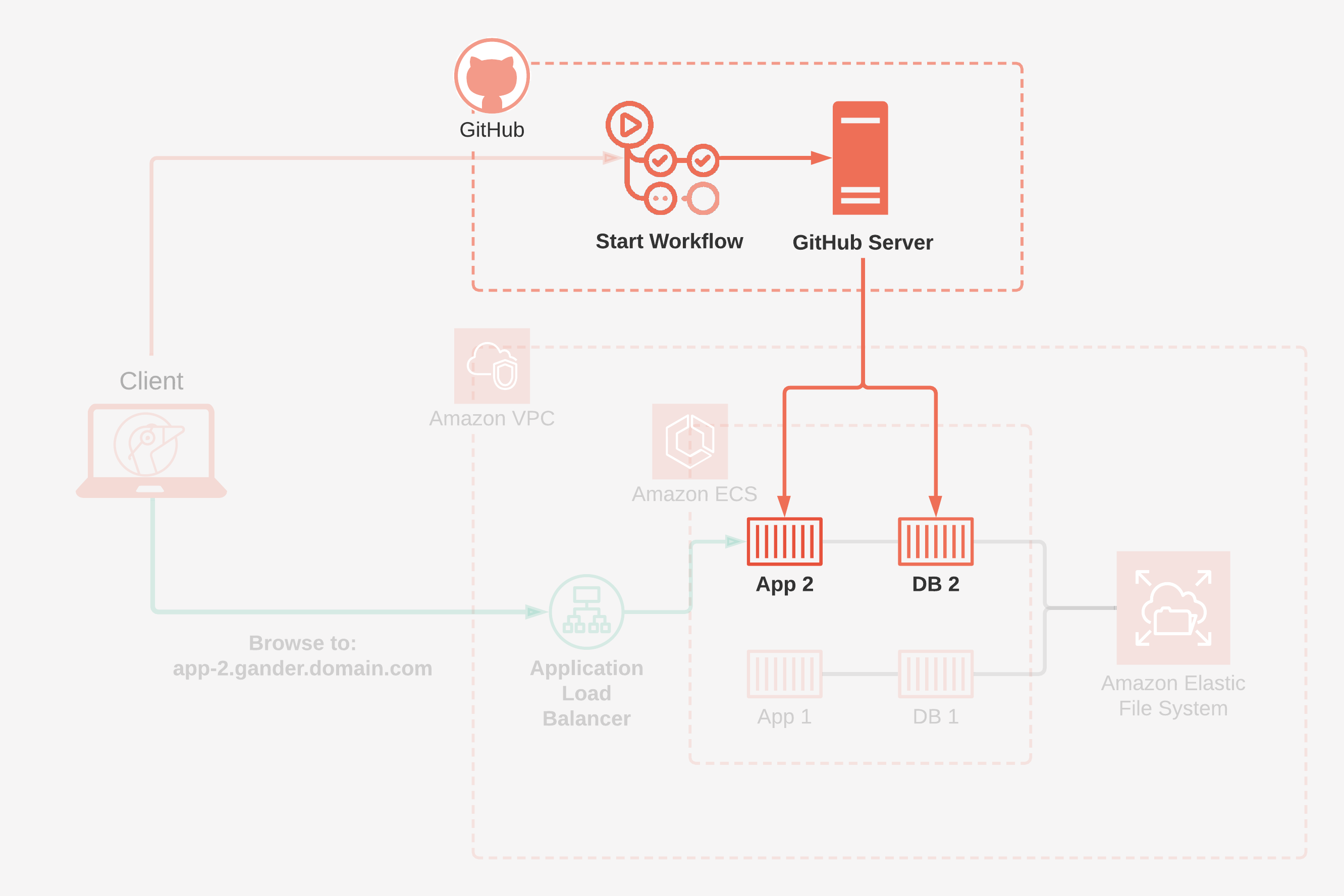
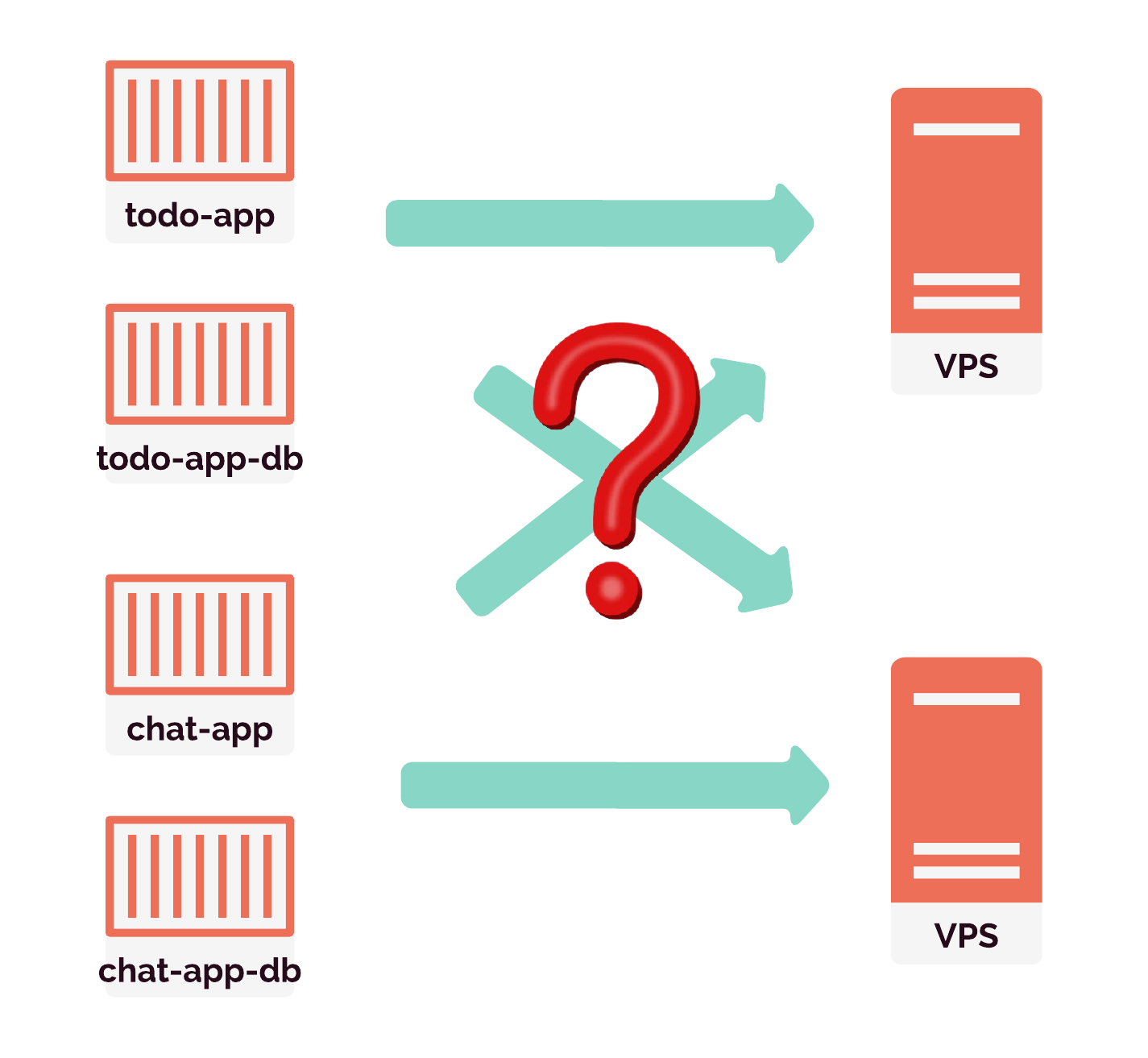
As users of Gander would want to deploy more than one review app, we need to find a way to host multiple review apps efficiently while keeping the apps and their data isolated from one another. But first we will take a look at the naive solution and what problems arise in taking this approach.
Recall that Gander only supports review apps for monolithic applications. These applications must have exactly two processes: an application and a database. The naive solution to hosting these applications is to provision a server and simply drop the application code and its database onto that server. This is called single tenancy.
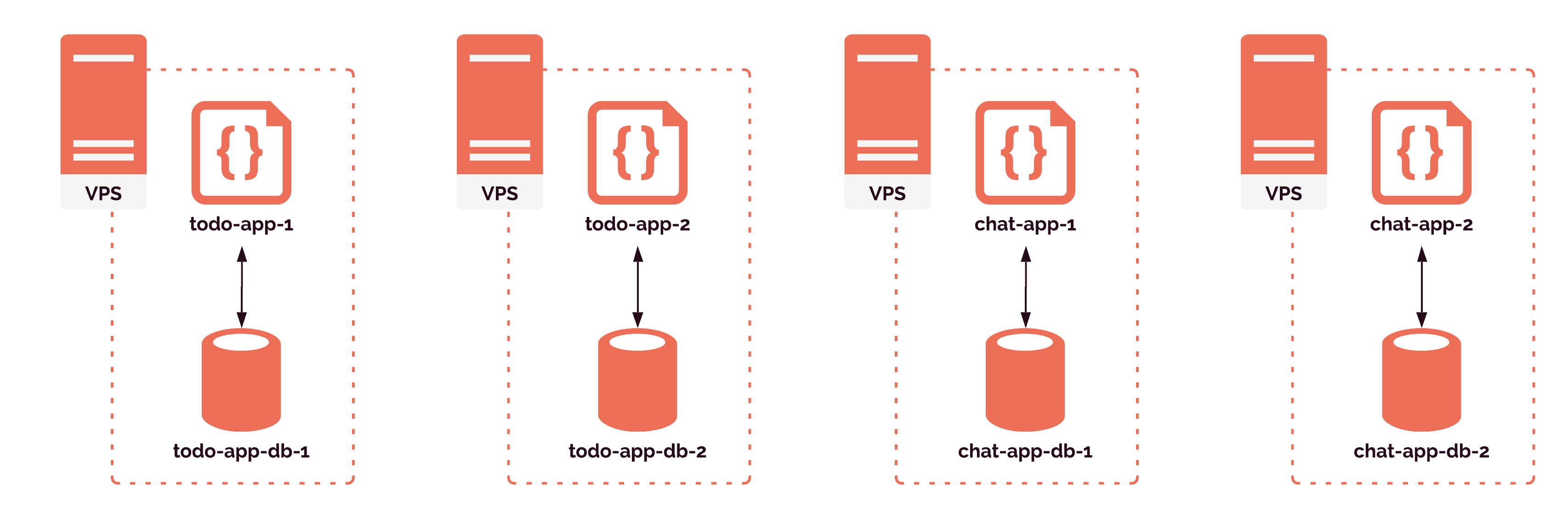
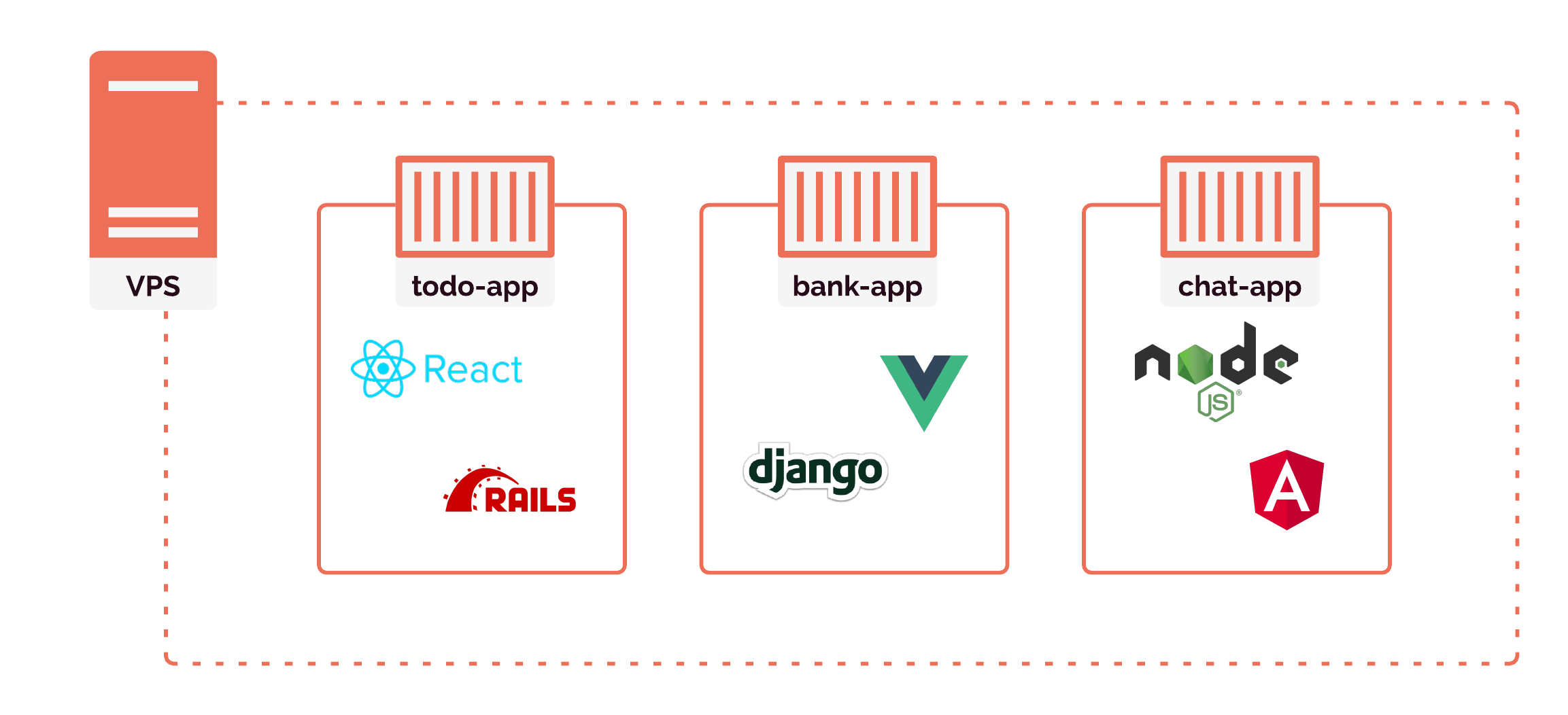
When it comes time to serve the review apps, we will want the capability to serve many review apps at one time. For example, we might need to serve a todo project's review app and a chat project's review app. And there might be simultaneous pull requests on the same project as well, such as a header feature and a sidebar feature for the todo project.
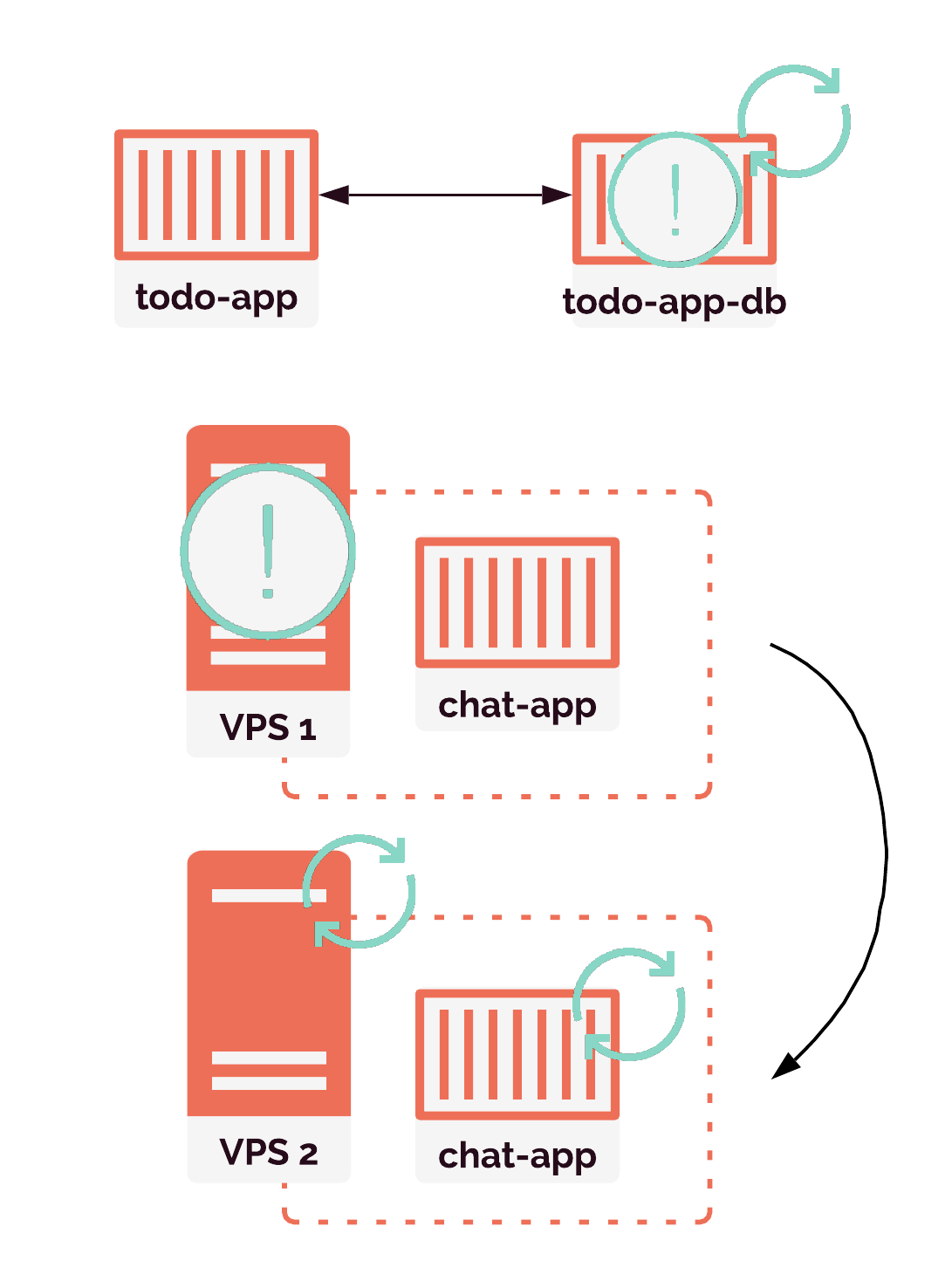
Dropping each review app onto its own server quickly becomes inefficient, resulting in poor resource utilization. As we would have multiple servers each running one app, most of the processing power, memory, and storage on the servers will go unused. A more resource-efficient alternative to single-tenancy is multi-tenancy — running multiple applications on the same server. But this creates a new problem: dependency conflicts.
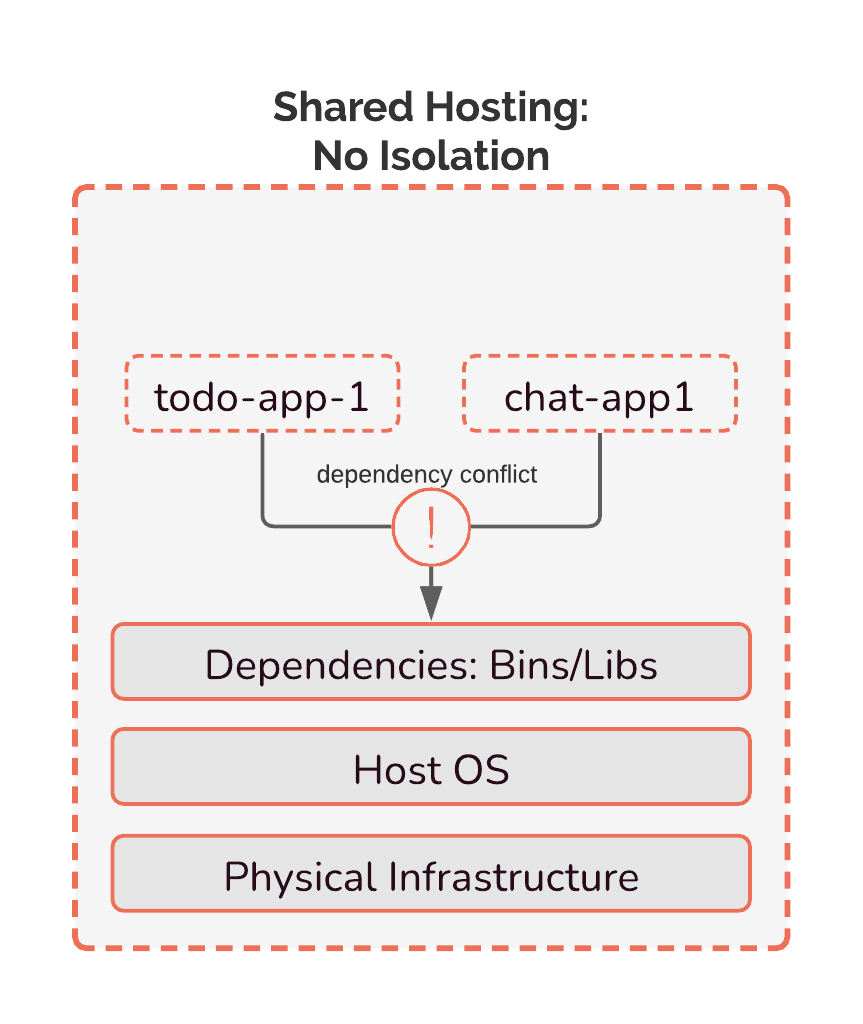
For example, if todo-app-1 depends on library 1.0.0, while chat-app-1 depends on library 2.0.0, one project's version of the dependency will overwrite the other. To keep the two versions of library separate, we would have to use a custom naming system or directory structure. With multiple apps and multiple dependencies, that type of work will grow in complexity as the number of conflicts grows.
Multi-tenancy creates security challenges as well. Apps on the same server would have the potential to access the file systems and memory space of other apps, and we want to avoid such security risks.
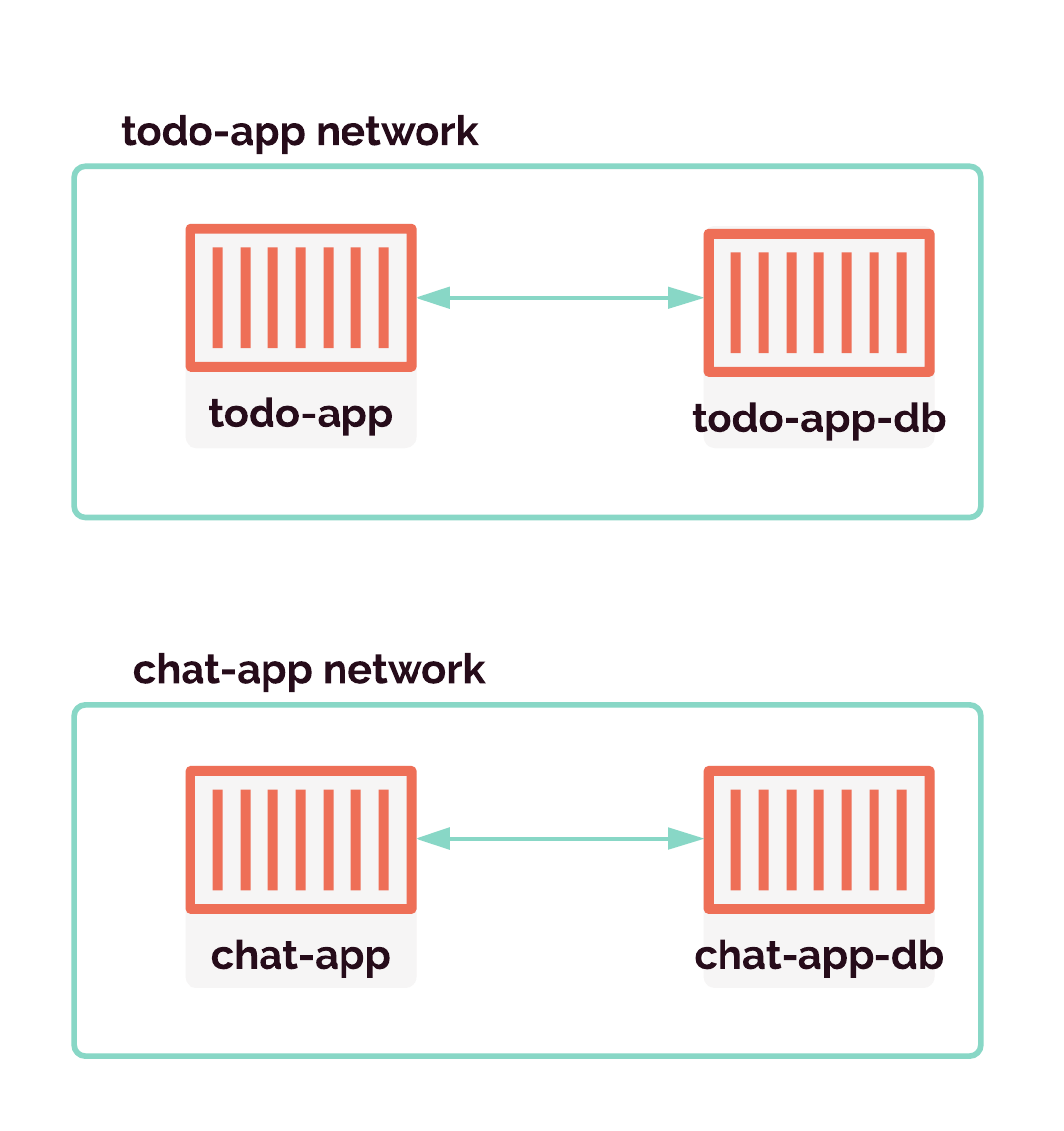
One method of isolating applications is to run them inside virtual machines. A virtual machine (VM) is essentially an entire computer running on software. It has its own operating system, and thinks of itself as a physical computer with its own CPU, memory, hard disk, and network card. The advantage of using virtual machines is that a host computer can run multiple virtual machines at the same time. Because of this, we can isolate dependencies between applications by having each application installed on its own virtual machine, and run many virtual machines on a single server to achieve multi-tenancy.
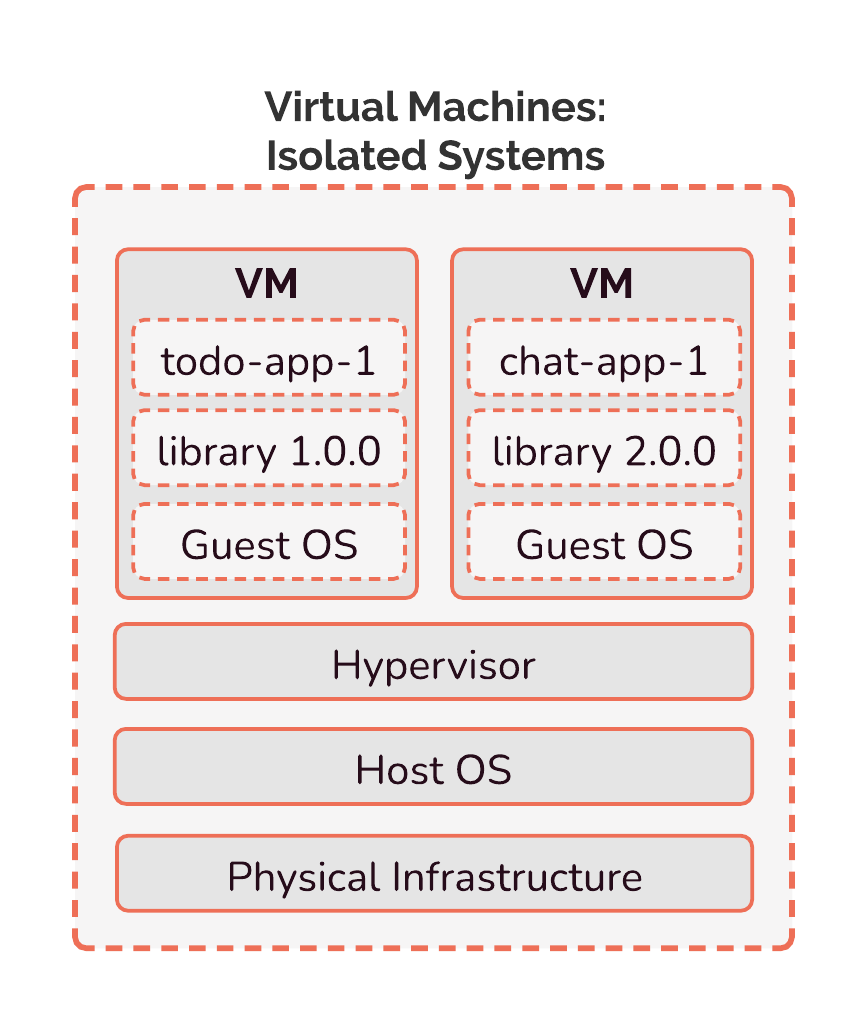
Because each VM thinks of itself as a physical computer, the server hosting these virtual machines uses a hypervisor to manage access to hardware. This is to avoid hardware access conflicts. Virtual machines are not without their problems, however. Because they run an entire operating system, including the kernel, drivers, and more, they use a lot of resources.
Containers, on the other hand, are lightweight. They still contain everything a software application needs to run, including the source code, dependencies, OS packages, language runtimes, environment variables, and so on. Unlike virtual machines, though, containers do not need to have their own operating system. Instead, they share the host operating system's kernel. Access to the kernel is regulated by the container daemon, which is responsible for managing containers on the server. Even though containers share the host operating system, they still view themselves as a complete, isolated system with their own filesystem, networking capabilities, and so on.
Because they don't have to run a complete operating system, they use significantly less resources, and are far more portable than virtual machines. This is the reason that we chose to use containers for Gander — containerizing allows us to have highly portable, isolated review apps.

Containers also give us the ability to implement multi-tenancy with projects that use a variety of languages and frameworks. Our architecture for managing review apps will interact with the apps at the container level, and will not need to know about what languages or frameworks are used inside the apps themselves. Each review app container will look the same as all of the others from outside of the container.
We run our databases in containers as well, which provides several benefits.
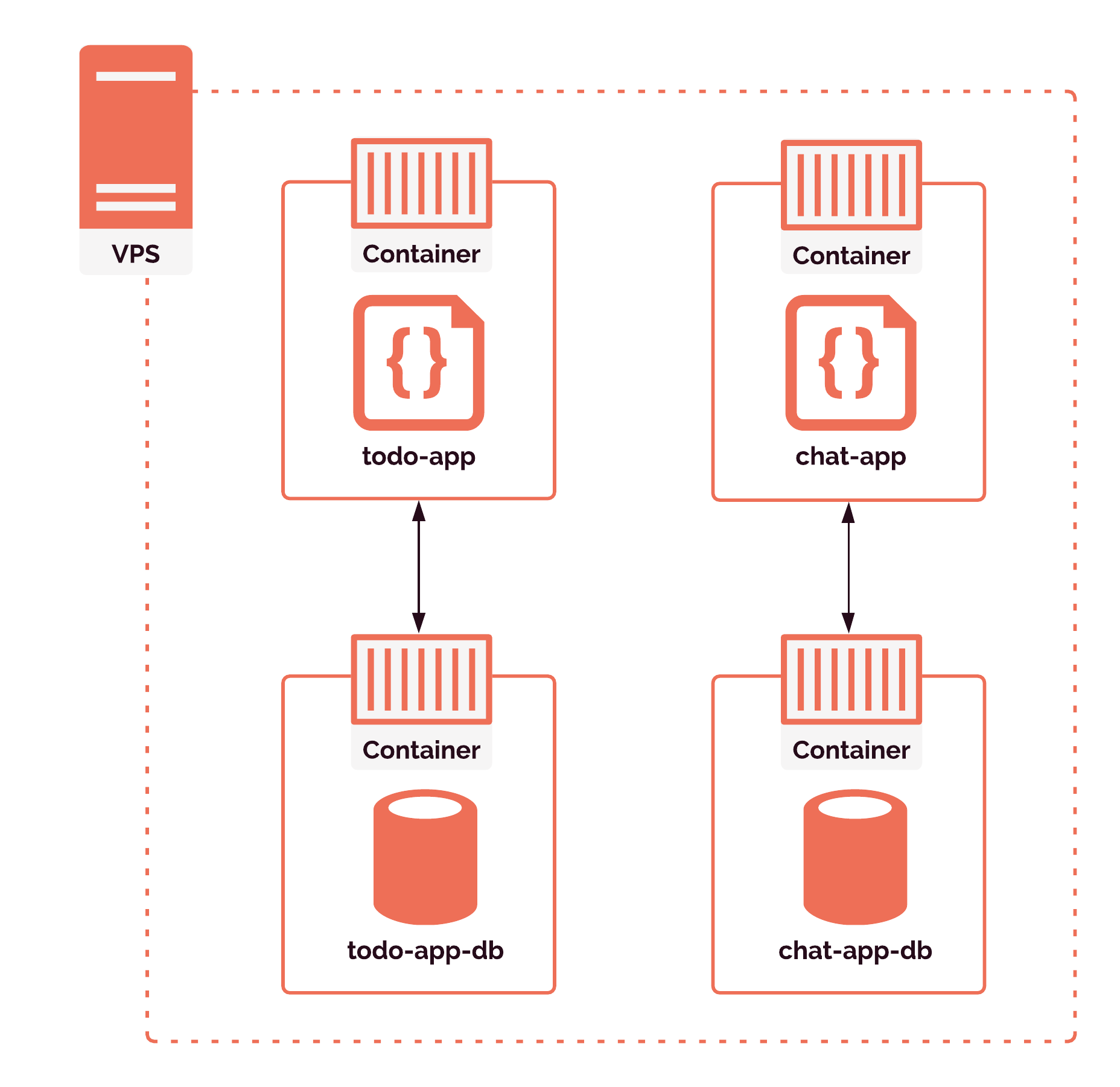
With containerized databases, we avoid the need to deal with any potential conflicts between databases running on the same machine, such as port conflicts or naming conflicts. If one database fails, the other review app won't be affected. So each of our review apps runs in two containers: one container for the application source code, and one container for the database.
Before a container can be brought to life, we must build an image. An image is a static, read-only template with instructions for creating a container, 9 while a container is an ephemeral process that runs from an image. Similar to how a class contains the blueprint for instantiating any number of objects of its type, an image contains the blueprint for running any number of containers based on its instructions. A built image is stored in a registry, and it will be pulled from that registry when it is time to run a container based on that image.

We can pull an image for our database container from a registry of pre-built database images because nothing about the database itself will be application-specific. The application image, though, is something we will need to build ourselves. Each application image will contain its unique application source code, application dependencies, environment variables, language runtime, language-level dependencies, and so on. Both the code and all associated dependencies will be completely different for every project.
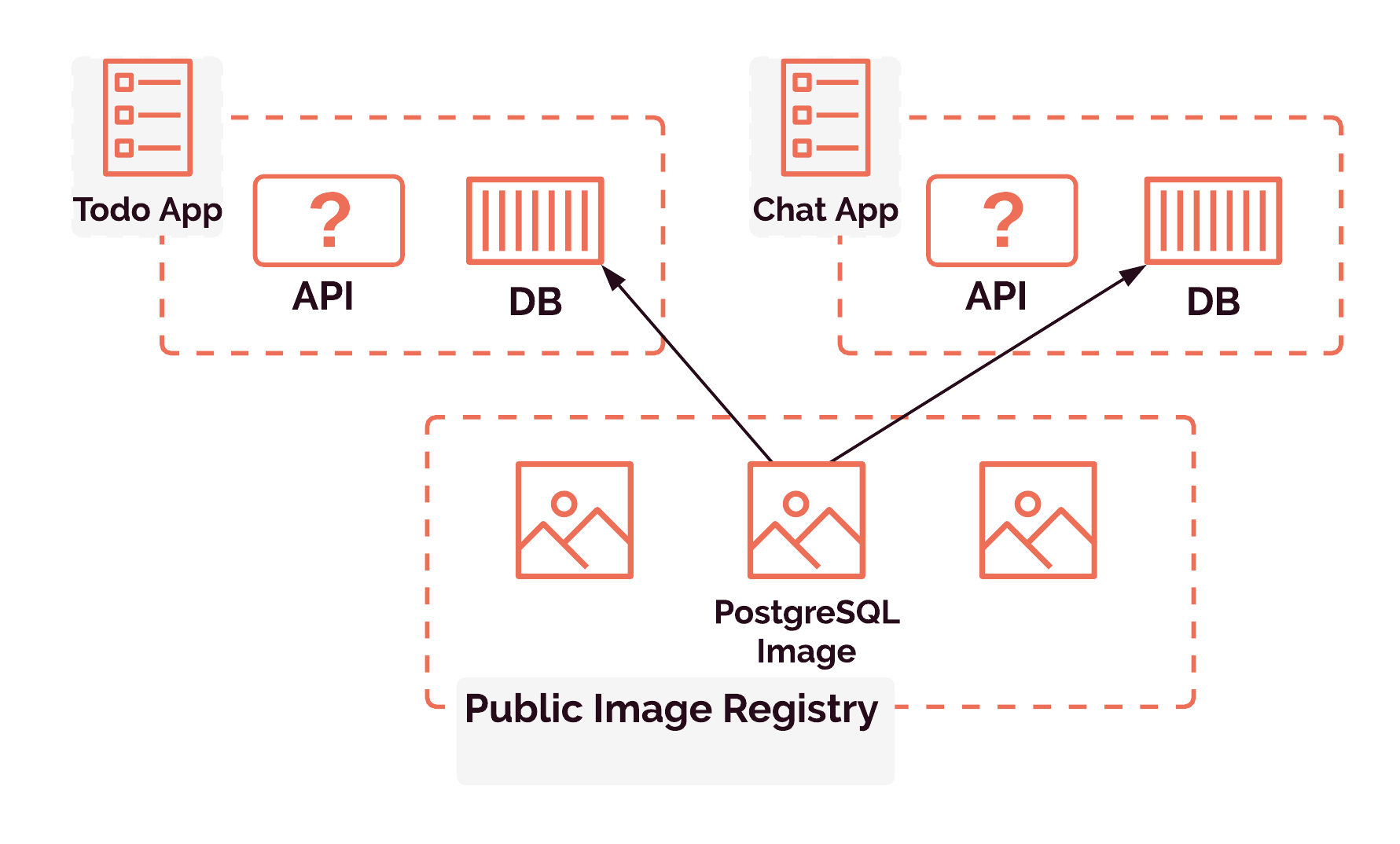
So how can we build this customized application image? To containerize such an application, we need to detect the language and framework the application code uses, install all the relevant dependencies, know how to start up the application, and collect the relevant environment variables. As one of our goals is to minimize the amount of setup and configuration required from Gander's user, we need an easy way to automate this application-specific configuration.
There are three ways we could choose to build our application container images.
Docker is the industry-standard tool used for containerizing applications and uses Dockerfiles to define the images. One option for containerization would be to have the user provide a Dockerfile. The main advantage of this option would be the ability to support any framework that the user might need, as long as the user can write a Dockerfile that will containerize their application. However, one of Gander's design goals is convenience for the end-user. To direct our design towards this goal, we would prefer not to require expertise with Docker and containers on the part of the user.
We considered a second option, where Gander would generate a Dockerfile for the user. This would improve Gander's ease-of-use and would help us reach our design goal. However, this choice would limit the types of frameworks we could support because we would need to write Dockerfile-generating code for every supported framework, one by one. Our list of supported frameworks would be restricted by the time we had available to write and debug framework-specific containerizing code.
The third option is Cloud Native Buildpacks, 10 a project by the Cloud Native Computing Foundation (CNCF). The CNCF is an organization dedicated to open-source projects that "empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds." 11 Many CNCF projects, such as Kubernetes, are container technologies.
Cloud Native Buildpacks is a container tool that transforms source code into a runnable container image using a three-stage process of detection, building, and exporting. The container images exported by Buildpacks are Open Container Initiative (OCI) compliant, meaning that they can be run by any container tool that uses the industry-standard OCI image specifications. AWS has no problem running these containers because it uses Docker, which is OCI-compliant.

Buildpacks are a powerful tool that can containerize a project without requiring the user to write any configuration files. How is this possible? First, the user must select a specific "builder" to apply to a project. 12 The builder then detects the project's language and selects from its arsenal of buildpacks as needed to execute the image build appropriately for that specific project. The buildpacks build the code into runnable artifacts, and those artifacts are transformed into a container image that is exported and made available for running a container.
Gander does the work of selecting the builder on behalf of the user, based on Cloud Native recommendations. These builders all support multiple languages, but we do ask the Gander user to indicate their project's language, to make sure that we choose the best builder possible. We use the Google Cloud Builder 13 for Python apps; the Paketo Base builder for apps written in Node.js, Golang, Java, or .NET; and the Paketo Full builder for apps written in Ruby or PHP. 14 Users can also write a Procfile with their app configuration information if they wish to be explicit and bypass the auto-detect functionality, in which case we use the Paketo Base builder.

Buildpacks give us the best of both worlds: simplicity for the user alongside support for multiple frameworks. So far we've successfully run review apps for projects written with Go, Node, Python, and Ruby. Buildpacks can also support .NET, PHP, and Java, and we plan to test these languages as well in future work.

Choosing to use Buildpacks was a straightforward decision and a win-win situation. Since Buildpacks have the power to containerize applications written in a wide variety of languages and frameworks using auto-detection, Gander does not need to automate containerization for many types of projects one at a time or require the user to write configuration files. The end result is that, as long as the user's project can be containerized with Cloud Native Buildpacks, then Gander can generate a review app for the project.
We've seen how GitHub Actions use container and Buildpacks technologies to build review apps. Now let's transition away from GitHub and begin looking at what happens when our Actions deploy review apps to the AWS component of Gander's architecture.
To serve several review apps we will need a way to manage the containers that our review apps run — two containers for each application. Managing these containers includes deciding which containers go on which servers and distributing the containers as efficiently as possible. We'll have to think about scaling up additional servers when needed as well.
We also want to keep our application available if a container fails, so our container management will need to include restarting on failure. If a container fails, we want to run another container from the same image in its place. A server might fail too, in which case its containers will also fail. Fixing this situation will require restarting a new server, and then running replacement containers on it.
We also need our containers to communicate with each other. The application API container and its database must be networked together into a group to form a review app. That container group has to know what order to start up containers in and how the containers relate to one another. Routing to these container groups also needs to be maintained even as individual containers fail, restart, and receive new IP addresses in the process.
All of these container management operations are normally grouped under the concept of "container orchestration". And so we needed to decide how Gander would handle container orchestration.
One option would be to manage container orchestration ourselves. Doing our own container orchestration would give us granular control over all aspects of it, including the opportunity to determine exactly how scaling and routing are set up and managed. Kubernetes and Docker Swarm are two popular solutions for container orchestration. Although these systems are highly configurable, they are very difficult to configure and manage.
Externally managed container orchestration, on the other hand, turns over the implementation details of orchestration to a service. Scaling and fault detection happen automatically. There are fewer options for configuration, but the benefit comes in the form of ease of use.
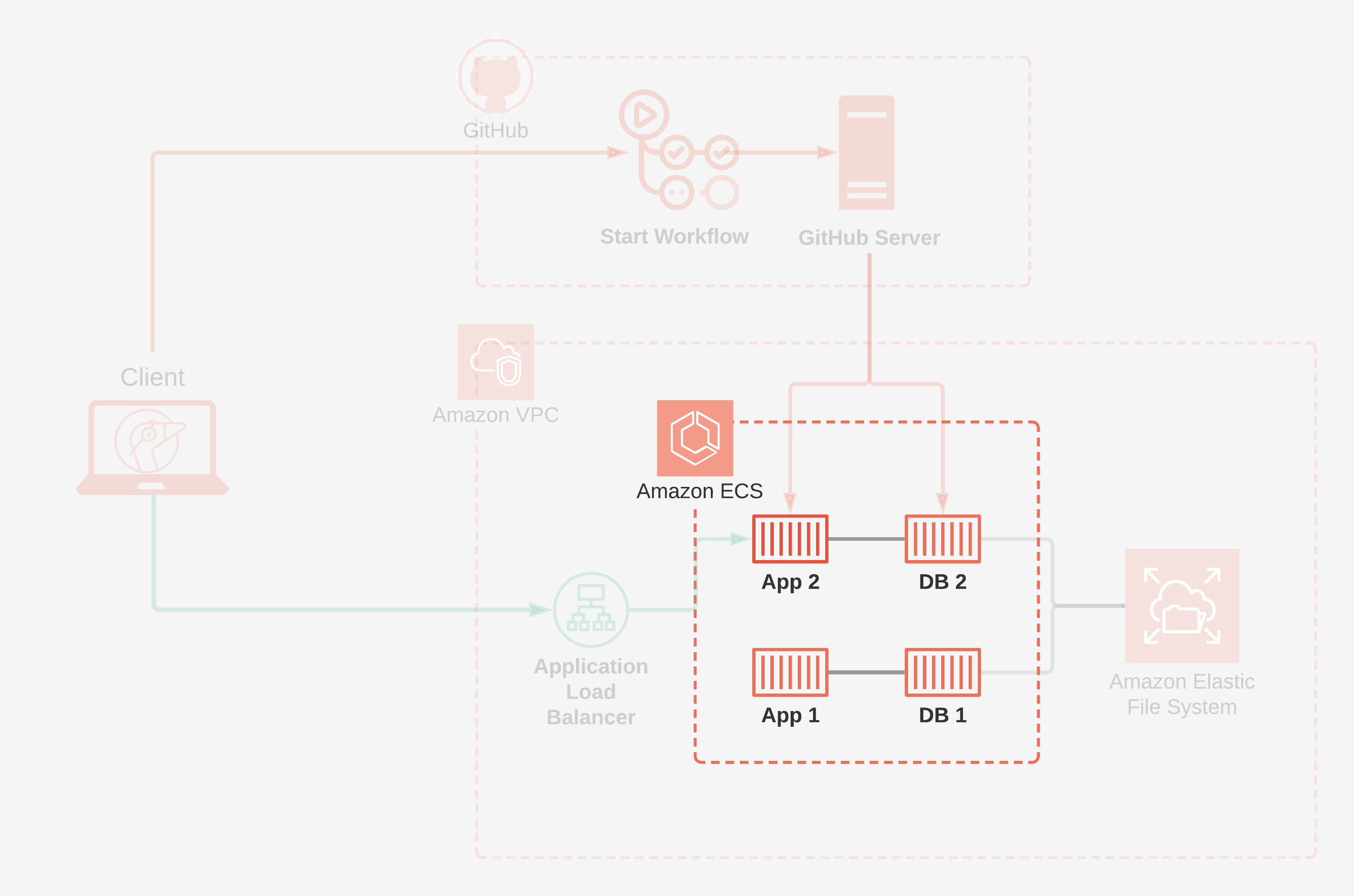
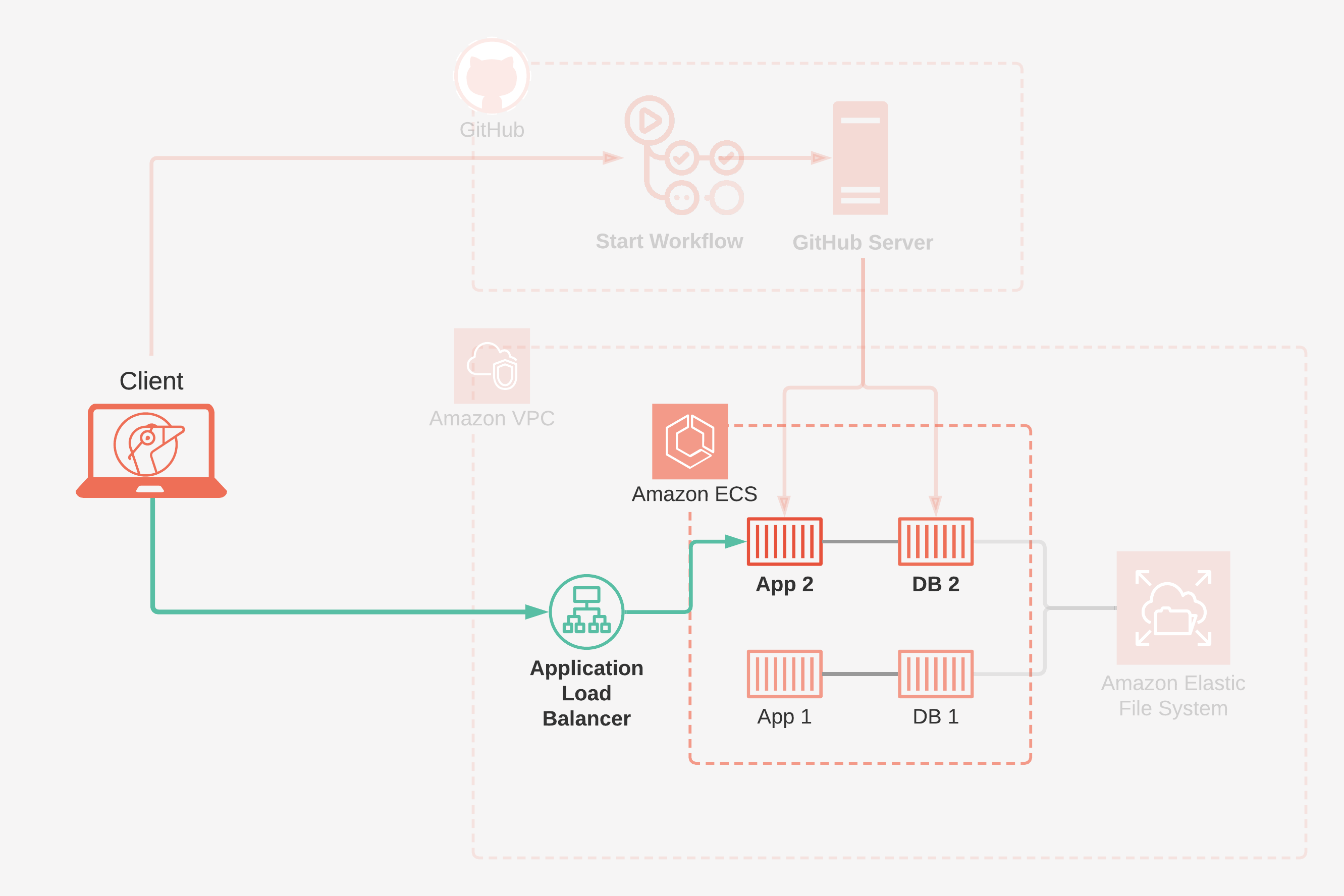
We decided to let Amazon ECS handle container orchestration for Gander review apps. Granular control over container orchestration is overkill for an application like Gander. Each review app only needs to manage two containers, and we won't ever be running enough containers to see any benefit from customized orchestration. We already knew we wanted to use AWS for our infrastructure, so this decision made a lot of sense for us.
ECS provides a convenient way to group our containers into review apps using tasks. Gander structures each review app into a task that specifies exactly two container images: one for the application and one for the database. These tasks are the fundamental unit that ECS manages. In practice, this means that ECS will make certain decisions on our behalf. It may decide to replicate certain containers within a task if it is receiving heavy load or restart a container whose CPU is overloaded. From outside of the ECS abstraction, all we care about now is that the task we defined is up and available. Ultimately, this extra layer of abstraction means we don't have to worry at all about actually managing the containers within a review app — ECS will handle all of that for us.
A Gander Review App on Amazon ECS
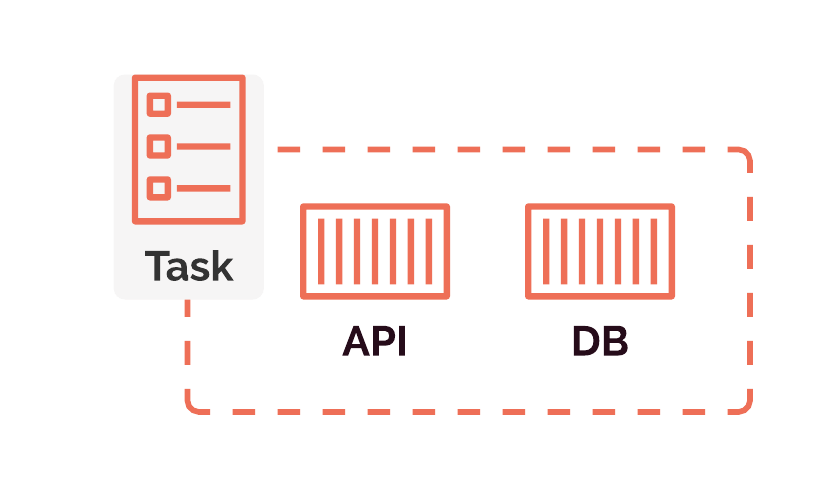
Defining our review apps as tasks allows us to deploy our containers as fully-formed review apps rather than as individual containers. The task definitions that we provide to ECS list the required container images and prescribe other constraints. These constraints include how much CPU and memory to use for each task, the startup command for each container, and so on.
With Amazon ECS handling container orchestration, containers and tasks will be managed efficiently and automatically. The next decision we had to make was whether or not to let Amazon ECS manage not just the containers, but the servers they live on as well.
Amazon ECS uses the term "launch type" to reference the type of server infrastructure that the user chooses for running their tasks. The first launch type, Amazon EC2 (Elastic Compute Cloud), allows the user some degree of control over the servers. The second option, AWS Fargate, abstracts away the servers completely.
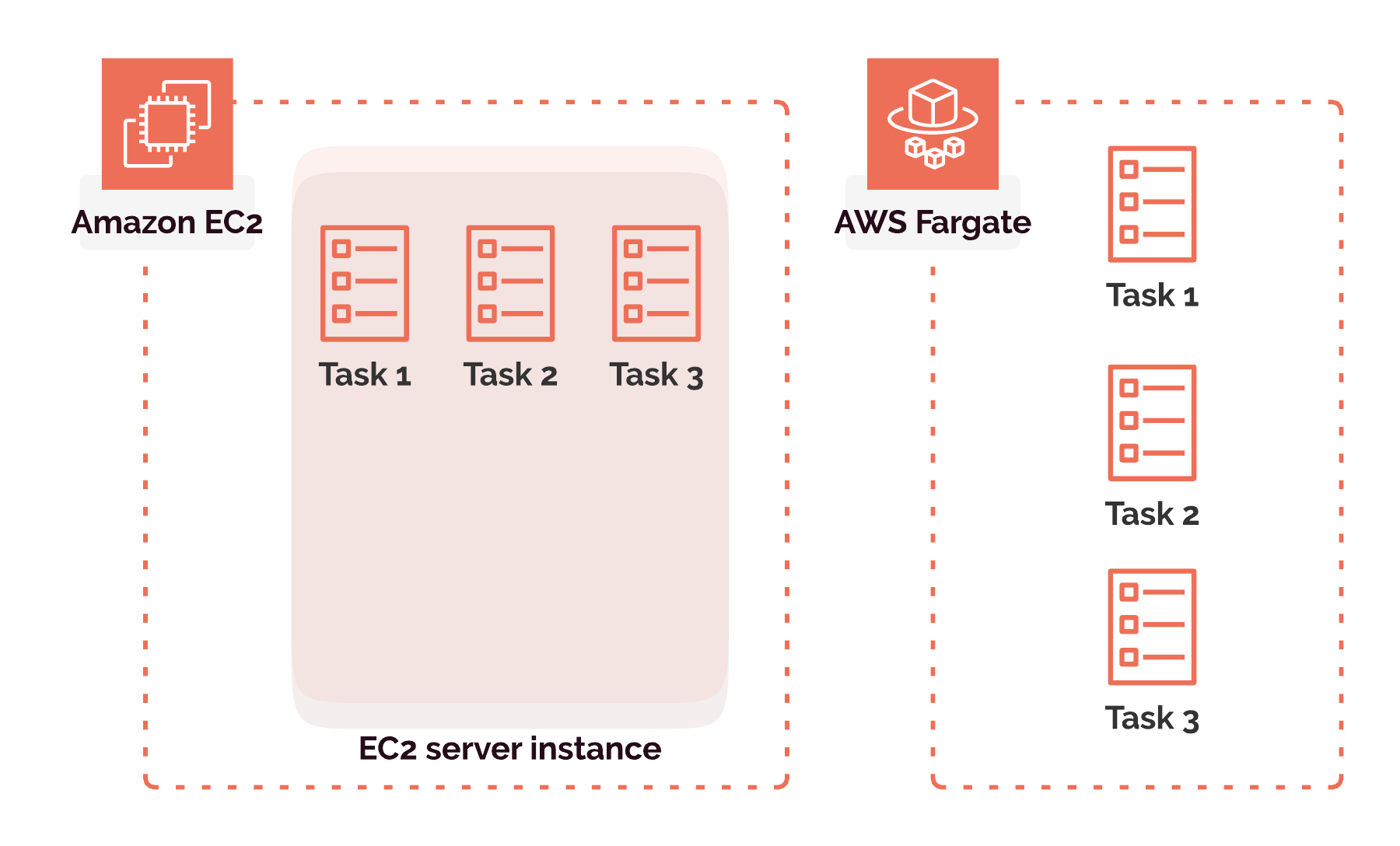
Using Amazon EC2 would give us control over the size and processing power of our servers, and access to their file systems. But we would also be responsible for keeping most of our servers' processing power and memory in use or end up wasting them. If our tasks leave servers mostly idle, we would be responsible for that.
AWS Fargate handles servers entirely on our behalf. The downside of that is that we have no choice in what type of servers host our applications, and no access to their files. But the advantage is that Amazon bears the responsibility for using servers efficiently and keeping them running near maximum capacity.
We chose to use Fargate rather than EC2 because Gander will only run a relatively small number of containers at any given time. It would be very difficult for us to occupy servers efficiently with a handful of ephemeral and isolated applications. 15
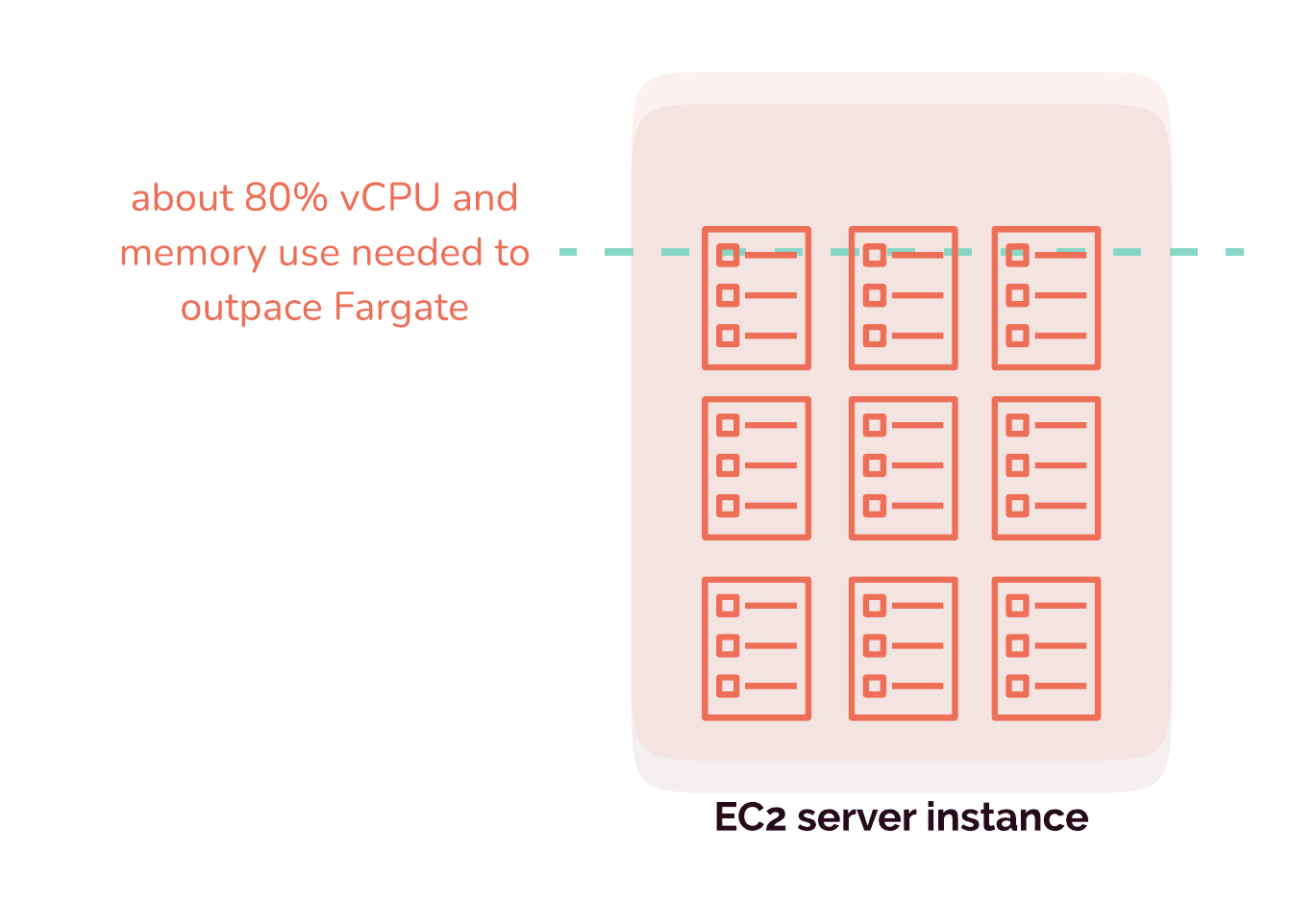
Variable workloads and uncertainty are problems for keeping servers running efficiently and near capacity, and Gander has both. After a review app is generated on a pull request, the app is spun up, but it might sit idle until much later when the reviewer has time in her schedule to access it. Even then, the workload required by the review app might be tiny. We are, furthermore, uncertain how many review apps will be running at any given time, and we don't know how many resources each review app will need. All of this makes a serverless option like Fargate a more cost-effective choice for our users, which is an important priority for us.
Of course, the tradeoff of using Fargate's serverless orchestration is that we are not able to access the host machines where our review apps live. We were able to compensate for this by using an external file system, as we explain in the next section.
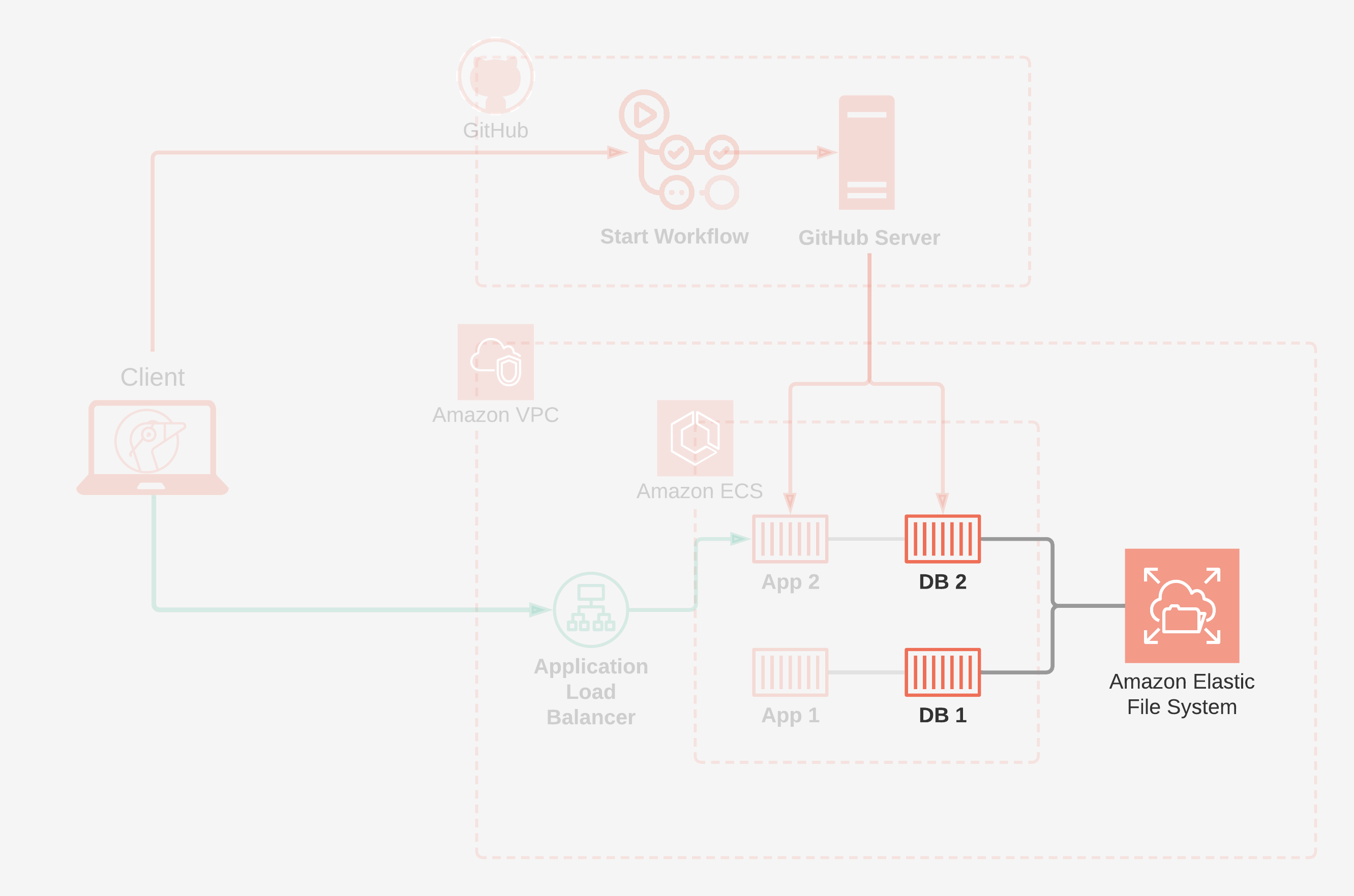
Now that we have a system in place that can build and manage multiple review apps, we need to address how they will persist their data. There are two parts to this — how do we store data when containers are involved, and where do we put it?
Since containers view themselves as complete operating systems, they have their own file systems. However, this file system is tied to the lifecycle of the container. So if the container were to restart due to a network fault, server failure, or application error, the data stored within would be irrecoverably lost.
In the case of review apps, failing to persist their data could lead to wasting organization time and resources. Imagine a QA tester testing a user sign-up workflow in which they create an account and fill out their profile. If there were a fault that caused the containerized review app to restart, the data they entered would be lost, and they would need to restart the sign-up flow. So for review apps, we'll need somewhere beyond the container filesystem to persist data.
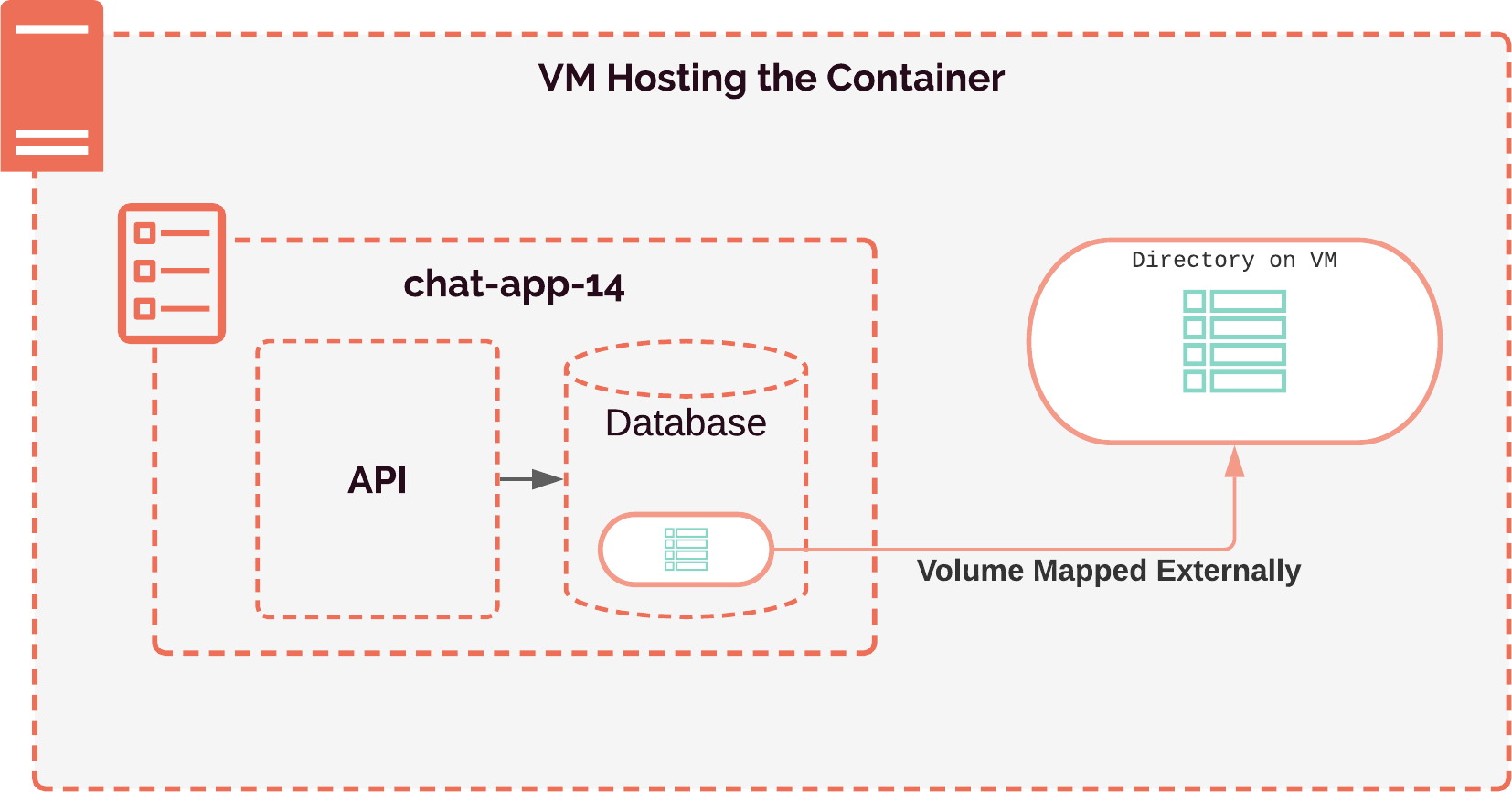
The typical way to persist containers' data is to connect containers to volumes. Volumes act as a symbolic link between a directory on the container's internal file system and the host machine's file-system. Using volumes, we can provide a place outside of the container for the database to write its data. Therefore, if the container restarts, the host machine's file system would persist the containerized database's data.
However, as we discussed earlier, we do not have access to the file system of the host machine when we use AWS Fargate to run our containers. This presents a problem, as we are not able to create the volumes we need in order to persist data.
Amazon's Elastic File System is a simple solution for this problem. EFS is a managed file system service that is available over the network. It scales automatically and is fault tolerant within a region. It still behaves like a local filesystem, but instead of existing on the same server as the container, it's accessed over the network. This allows us to create volumes much in the same way as using the local file system of the hosting server. By using EFS, we are able to store the PostgreSQL data in a robust way, ensuring the review apps have a stable and available form of data persistence.
Now that we know where to persist the data for our database-backed review apps, we have to address another problem — these databases need to be initialized in order to be used.
When we start a Postgres container, it starts up as a completely bare database. There is no defined schema. If the Postgres data directory within the container is empty, it will look for an initialization script which will define the schema the database will use, and also any seed data the developer wants to include. In order to seed the database with the user-provided schema and seed data, then, we had to figure out a way to place the initialization script in a location accessible to the Postgres container.
In our case, this presents a problem. In order for the Postgres container to have access to this initialization script, it either needs to be inside the image when we start the container, or in a place that we can access, such as Elastic File System. In the next two sections, we'll cover each of these ideas and the trade-offs associated with them.
Our first thought was to extend the public Postgres container image so that it has our initialization script already inside. This can be done easily, by writing a Dockerfile that copies the initialization script into the database's entry point directory, and then we can use that custom Postgres image instead of the default Postgres image. We would have to upload this container image to the same registry as our application server. When we run this custom Postgres container, it would then be able to initialize the schema and data so that the application can use it. Such an image would have roughly the same size as the Postgres image, which is about 315MB.
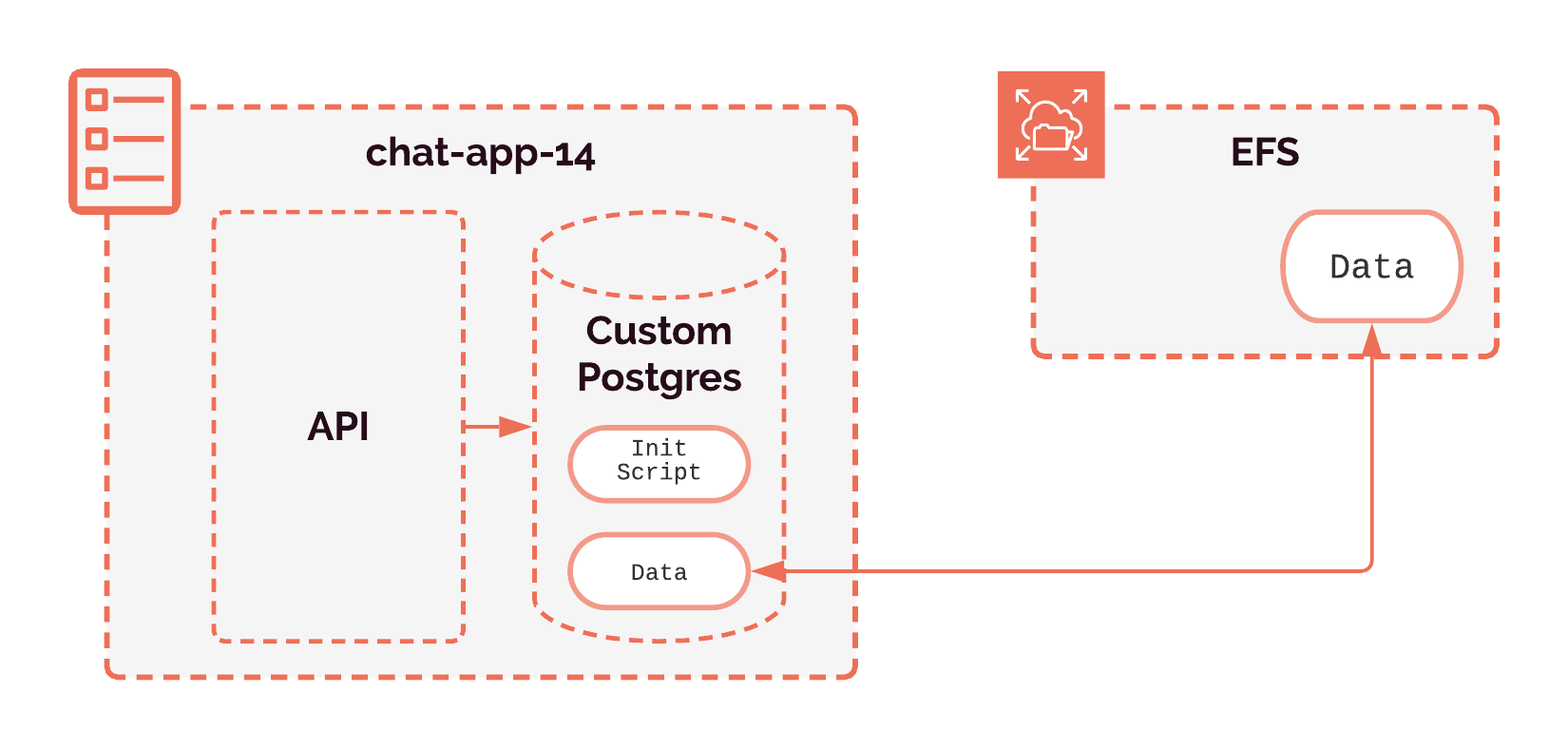
Another potential solution is to run a separate task before starting the review app. We can create this by making a container image based on a lightweight Linux image, with the initialization script copied inside. This container's sole job would be to copy the initialization script into a directory on the Elastic File System for the database to access. This way, when the database is started, it can access the initialization script because it is present on the Elastic File System. The total container size of this solution is about 5MB.
Our choice was to run a separate task before starting the review app. We want these review apps to start up quickly, and we didn’t want to unnecessarily download the Postgres image only to re-upload it with a small change. The total network throughput of using the custom Postgres image is about 630MB because we have to download it, build the custom Postgres image, and then re-upload it to the user’s Elastic Container Registry (ECR). Doing so would incur a greater data transfer cost to Gander users than using the lightweight Linux image, which has a size of only 5mb — making the choice clear.
Now that we can orchestrate our containers and run them in a way that allows them to communicate to their database, persist data, and initialize their schema, we have another problem to solve — how do we route traffic to these isolated review apps?
When a task is started on ECS, an Elastic Network Interface is provisioned. This is an Amazon-specific implementation piece and can be thought of simply as a software network card dedicated to the task. These network interfaces are automatically assigned a unique, auto-generated DNS name upon creation. One approach to solving the problem of routing would be to simply use this domain name, and comment on the pull request with this link.
However, this solution presents a problem. If the task were to restart due to an error in the container orchestration engine, an application error, or a failure of the host server, there would be a new ENI provisioned with a new DNS name. In this scenario, the link we post in a comment on the pull request will no longer be accurate. Our solution should be able to cope with restarting tasks, which means using the DNS names of the network interfaces is not an option.
To solve this problem, we need to be able to route a stable, user-facing URL to the correct review app. A server that routes incoming traffic to a pool of many servers is called a load balancer. 16 Load balancers are generally used to reduce load on each individual application server. There are essentially two types of load balancers offered by Amazon: layer 4 load balancers and layer 7 load balancers. Layer 4 load balancers operate at the transport layer and route traffic based on network-level information such as ports and IP addresses — information about the message itself is not available to a layer 4 load balancer.
For our use case, the main functionality we need is routing traffic to the corresponding review app — if a user requests todo-app-9.gander.my-domain.com, the load balancer should direct it to the todo-app-9 review app. We can't do load balancing based on IP or port because we wouldn't have enough information to route traffic to our review apps without introducing a unique IP address or non-standard port for each review app. This means that we can't use a layer 3 or 4 load balancer.
Amazon offers a managed load balancer, called the Elastic Load Balancer, due to its ability to automatically scale based on usage. Within this offering they have what they call an Application Load Balancer, which operates as a layer seven load balancer, routing and can route at the application layer. When a pull request is created, we can create a target group for the service, which means that any tasks created within the service will automatically be registered to the load balancer. This target group has a rule which tells the load balancer which subdomain will route traffic to that application. Because the target group is attached to the service, if a task were to restart due to any of the aforementioned reasons, it will be re-registered automatically to the load balancer, ensuring our links never break.
We've now finished exploring the AWS side of Gander. We saw how Amazon ECS hosts and manages review apps. We looked at how data persists in Amazon EFS. And we saw how our traffic routes through an Application Load Balancer.
The only piece of the architecture we haven't yet considered is Gander's command line interface. So let's take a look! You can get Gander up and running with just two commands.
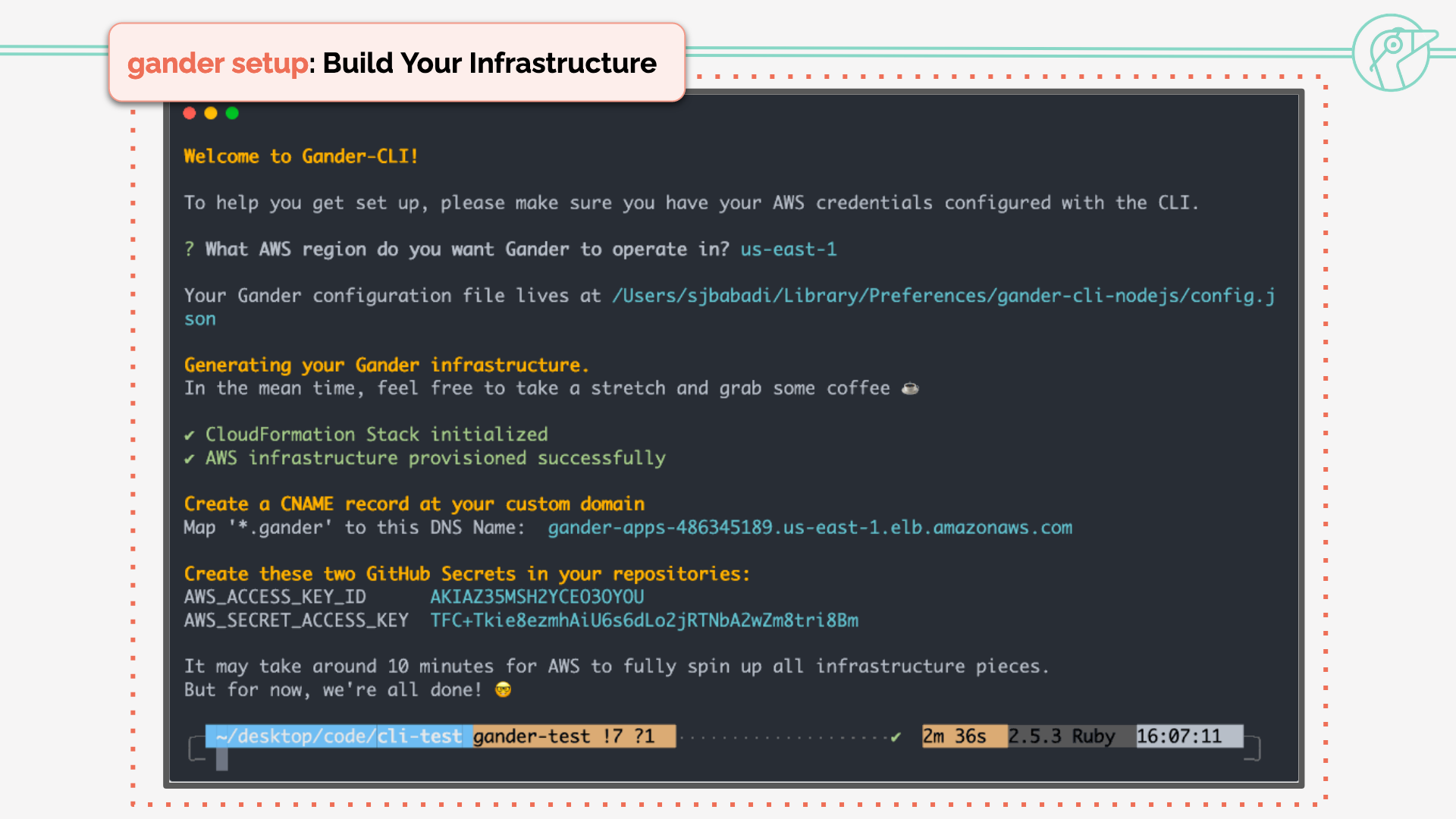
gander setup provisions and configures all of the necessary AWS infrastructure. This
infrastructure persists and receives all review apps from any Gander repository. You can see what happens during
setup in this screenshot.
gander init sets up the GitHub piece of Gander by loading the workflow files into the repository.
Here's an example of initialization for a Node.js repository.
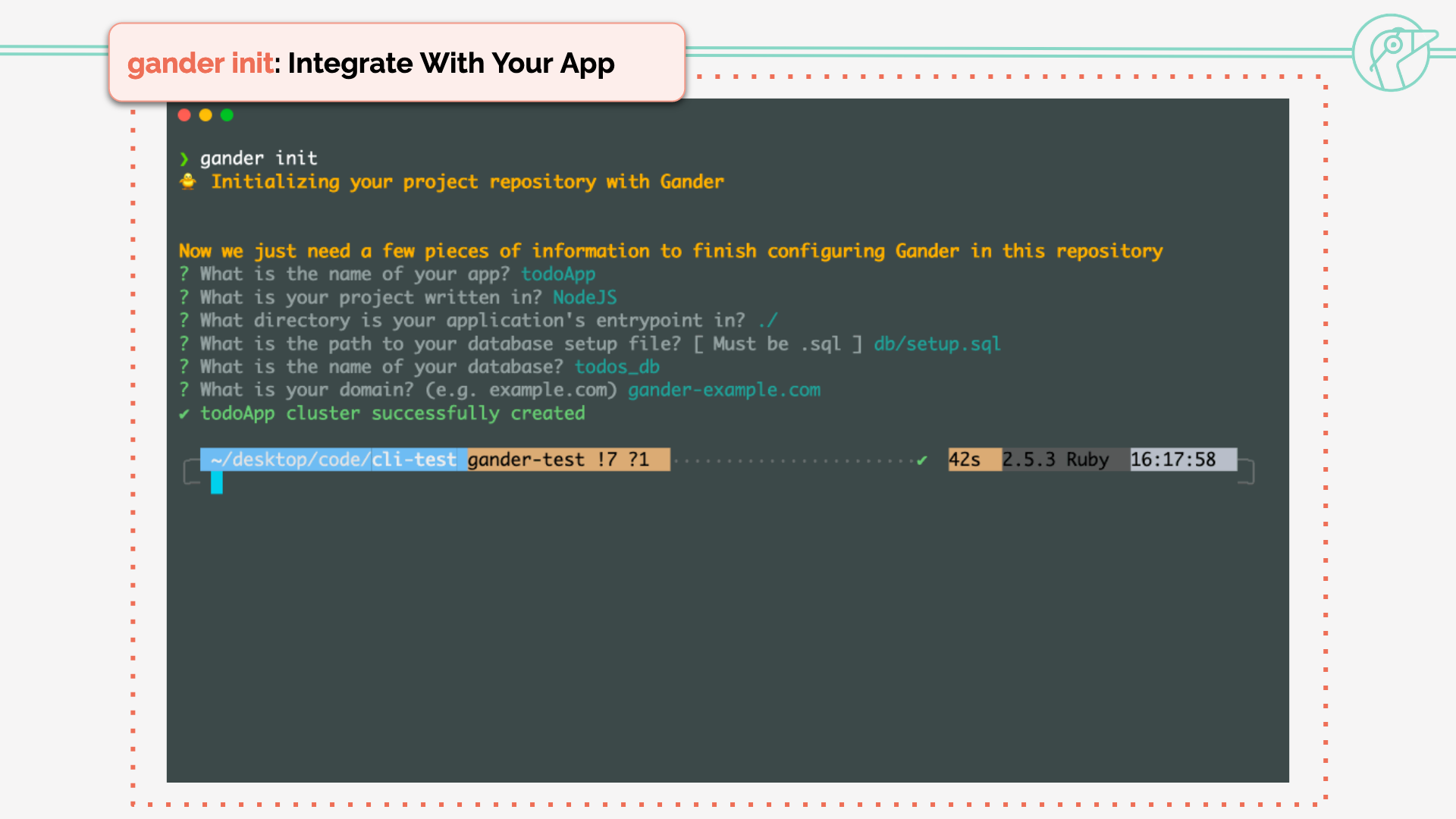
After that, Gander will create an isolated review app for each PR within each initialized repository. Each PR
will receive its own semantic link starting with <APP_NAME>-<PR_NUMBER>.
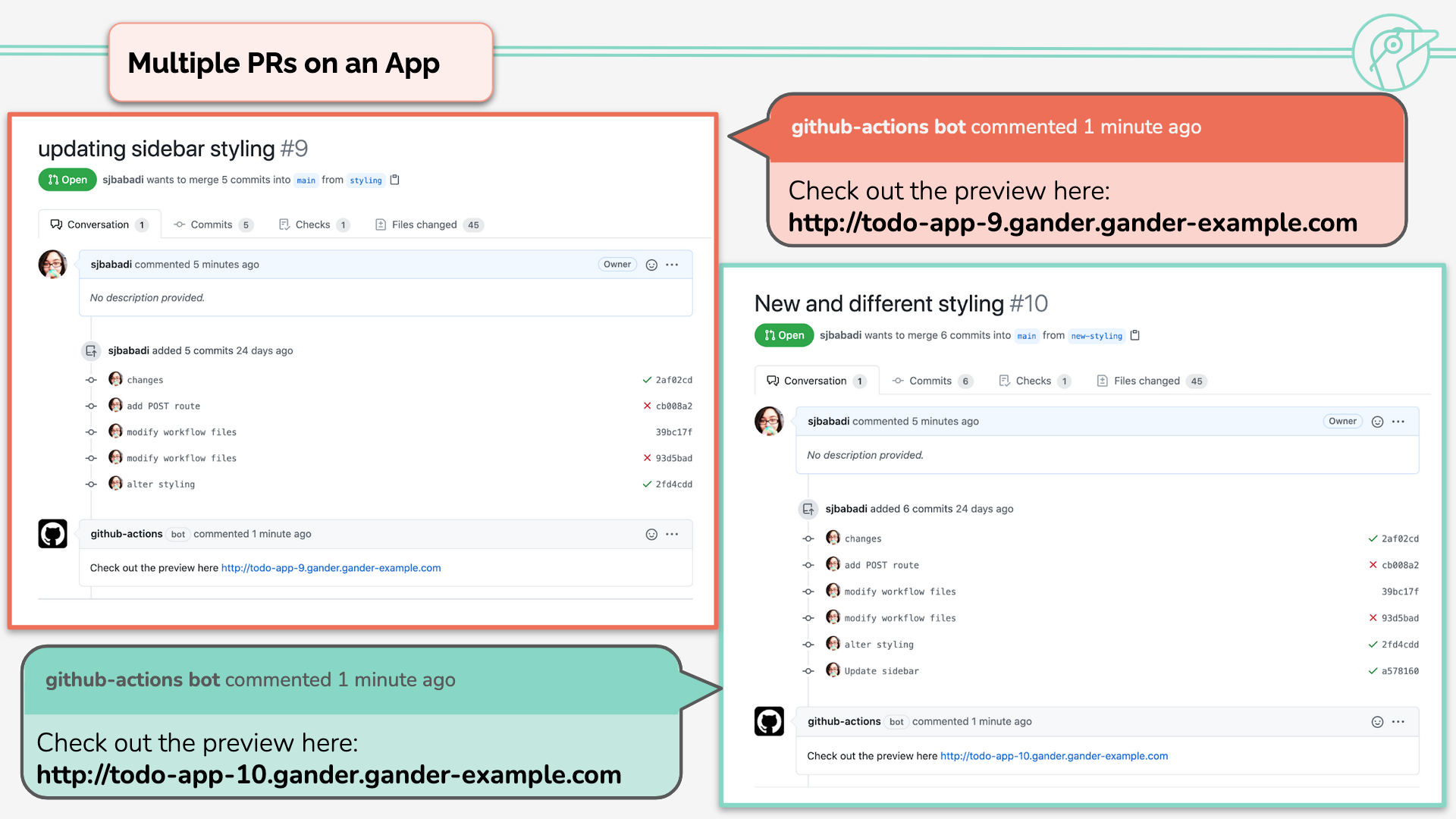
Each review app receives its own isolated database, thus previewing each new feature truly in isolation. As multiple review apps can be deployed simultaneously, reviewers can preview multiple features side by side. If the code is modified before closing or merging the pull request, the application is torn down and rebuilt based on the new commit. And when the pull request is closed, the relevant containers are destroyed.
Currently, Gander only supports PostgreSQL as a database. In the future we would like to support other relational database management systems, like MySQL, and other non-relational databases, such as:
Currently, we rely on Cloud Native Build Packs to set up the entrypoint command for our containers. For some frameworks, this is a problem because they require an explicit startup script to be used. This feature will allow us to generate review apps for a wider variety of frameworks.
This feature would allow us to add runtime to the seeder task, and execute a user-provided command within the context of the application before the review app starts up. One example would be to run rails db:setup during the seeding task, instead of simply placing a .sql file in the EFS directory where our database containers will look for them.
We are looking for opportunities. If you like our project, feel free to reach out!

Jacksonville, FL


Incline Village, NV

Austin, TX

Los Angeles, CA
